20. 在实际落地中,你觉得 RAG 最难的地方是哪里?
20. 在实际落地中,你觉得 RAG 最难的地方是哪里?
👔面试官:RAG 你也做了一段时间了,你觉得实际落地中最难的地方在哪?
🙋♂️我:我觉得最难的是 Embedding 模型的选型,模型不好向量就不准,后面效果肯定差。
👔面试官:Embedding 选型确实重要,但你说的是其中一个点,我问的是整体上最难的地方。而且你只说了模型,那文档解析乱码、chunk 切割不合理、效果没法评估这些问题呢?
🙋♂️我:对对,还有 chunk 切割也很头疼,切大了检索不准,切小了上下文丢了。
👔面试官:你这东一榔头西一棒槌的,说了半天也没个体系。我问的是你怎么系统地看待 RAG 落地的难点,能不能把它分层说清楚。
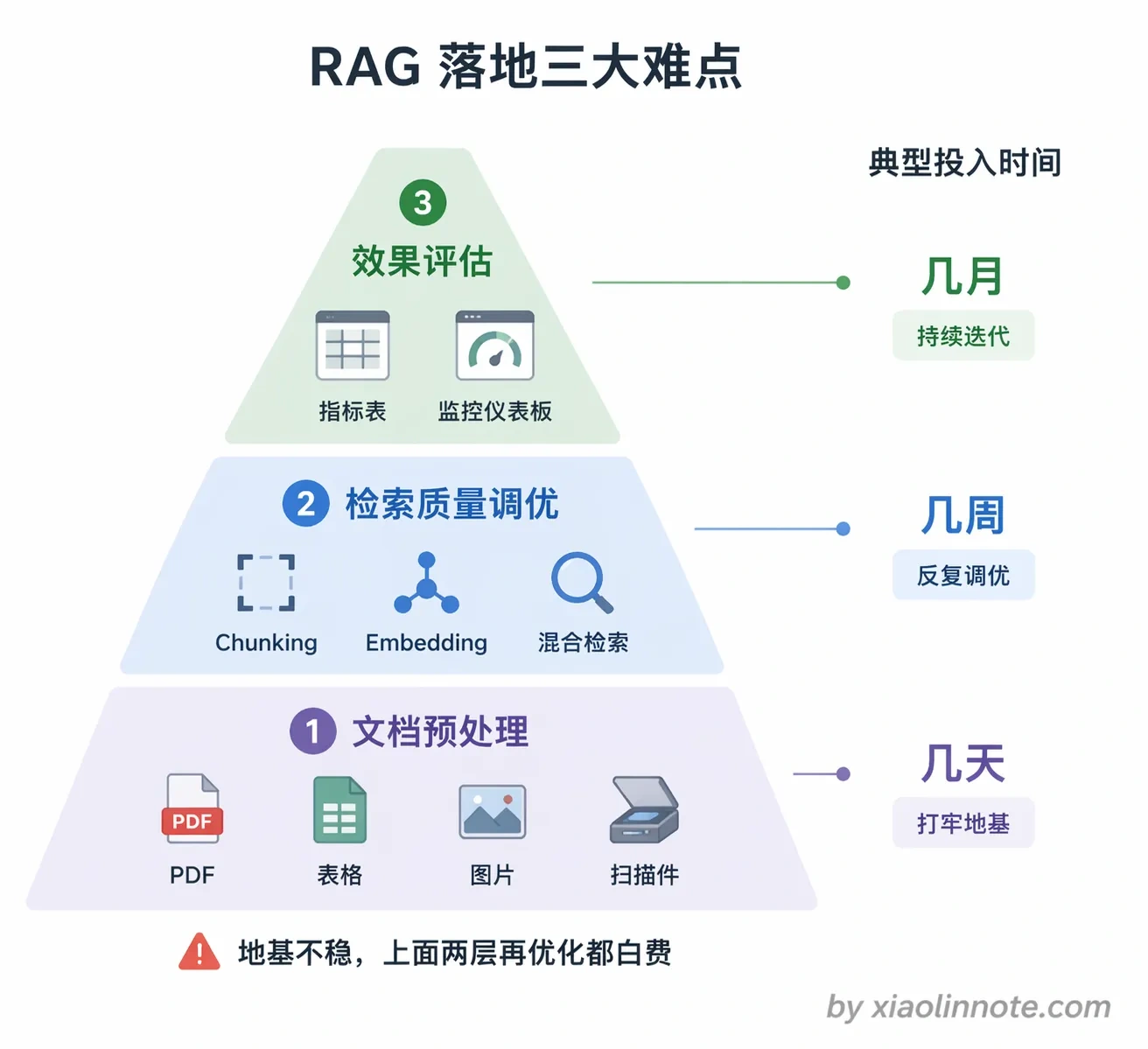
让我们来系统地梳理一下 RAG 落地过程中最难啃的几块骨头。
💡 简要回答
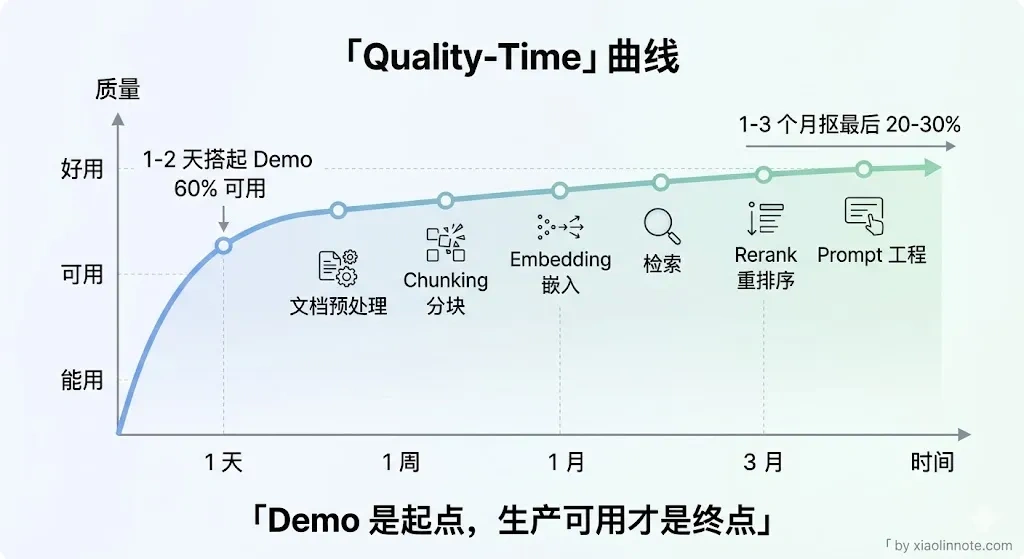
我觉得 RAG 最难的不是把它跑起来,一个基础的 Demo 一两天就能搭起来,难的是把它调好。工程上最让我头疼的有三块。
第一是文档预处理,原始数据的格式五花八门,PDF 里面的表格、图片、嵌套的格式,处理不好就是一堆乱码进了知识库,进去的是垃圾出来的也是垃圾。
第二是检索质量的调优,向量召回不准是整个系统效果的天花板,但问题来源很多,Chunking、Embedding、Query 改写,任何一个环节出问题都会影响结果,排查起来很费劲。
第三是效果评估,答案对不对很难系统性地衡量,不知道是哪个环节出了问题,优化就变成了瞎猜。
📝 详细解析
第一难:文档预处理
RAG 系统的效果受多个环节影响,文档预处理是最前面的一环,这一环做不好,后面所有的 Chunking、Embedding、检索、生成优化再牛也难救回来,因为你给系统喂的原料本身就是烂的。换句话说,文档预处理不是唯一的瓶颈,但它是一个「地基型」的瓶颈——地基歪了,上面盖得再漂亮的楼也容易塌。这一步看起来简单,实际做起来是最脏最累的工程活。
你可能会想,文档预处理不就是读文件吗?有什么难的?难就难在现实世界的文档格式五花八门,远比想象中复杂。
最常见的问题是 PDF 解析。pypdf 这类通用 PDF 操作库主要做的是文本流提取,它的定位就不是为复杂排版设计的,所以遇到带表格、双栏、嵌套的 PDF 会把内容顺序搞乱,表格里的数据会被解析成一行乱序文字,双栏排版的内容会混在一起。这不是 pypdf「不行」,而是它的工具属性,表格和复杂版面应该交给 pdfplumber、unstructured 这类专门优化过结构化提取的库。

举个具体例子,一个产品规格表的 PDF,原本是整齐的三列:型号、内存、价格,每行一个产品;被 pypdf 解析出来之后,可能变成一串没有分隔的乱码文字「型号内存价格iPhone 158GB5999」,行列关系全没了。
这样的内容存进向量库,不管 Embedding 模型多好,检索出来也是废的。进去的是垃圾,出来的也是垃圾。
处理方案是用更强的解析工具,比如 pdfplumber 专门处理表格、unstructured 库对不同格式做专项处理,或者对高价值文档直接用多模态模型(比如 GPT-4o Vision)来理解 PDF 截图。用 Vision 模型的代价通常比普通 Embedding 高几十到上百倍(按 token 单价),所以这条路只适合单价高、内容复杂、且数量可控的文档,比如合同、财报、专利,不适合海量普通文档。
除了 PDF,还有扫描版文档(需要 OCR)、包含大量图片的文档(图片里的关键信息文本提取不到)、代码文档(代码块切割不当会破坏逻辑完整性)。每种格式都是一个坑,真正的生产系统文档预处理的代码量往往比 RAG 核心逻辑还多。
第二难:检索质量调优
文档预处理保证了输入质量,但如果检索这一步不准,前面的努力就全白费了。检索质量是整个 RAG 系统效果的天花板,检索召回不到相关内容,后面的 LLM 再强也没用。但检索质量差的原因可能来自好几个地方,定位起来特别麻烦。
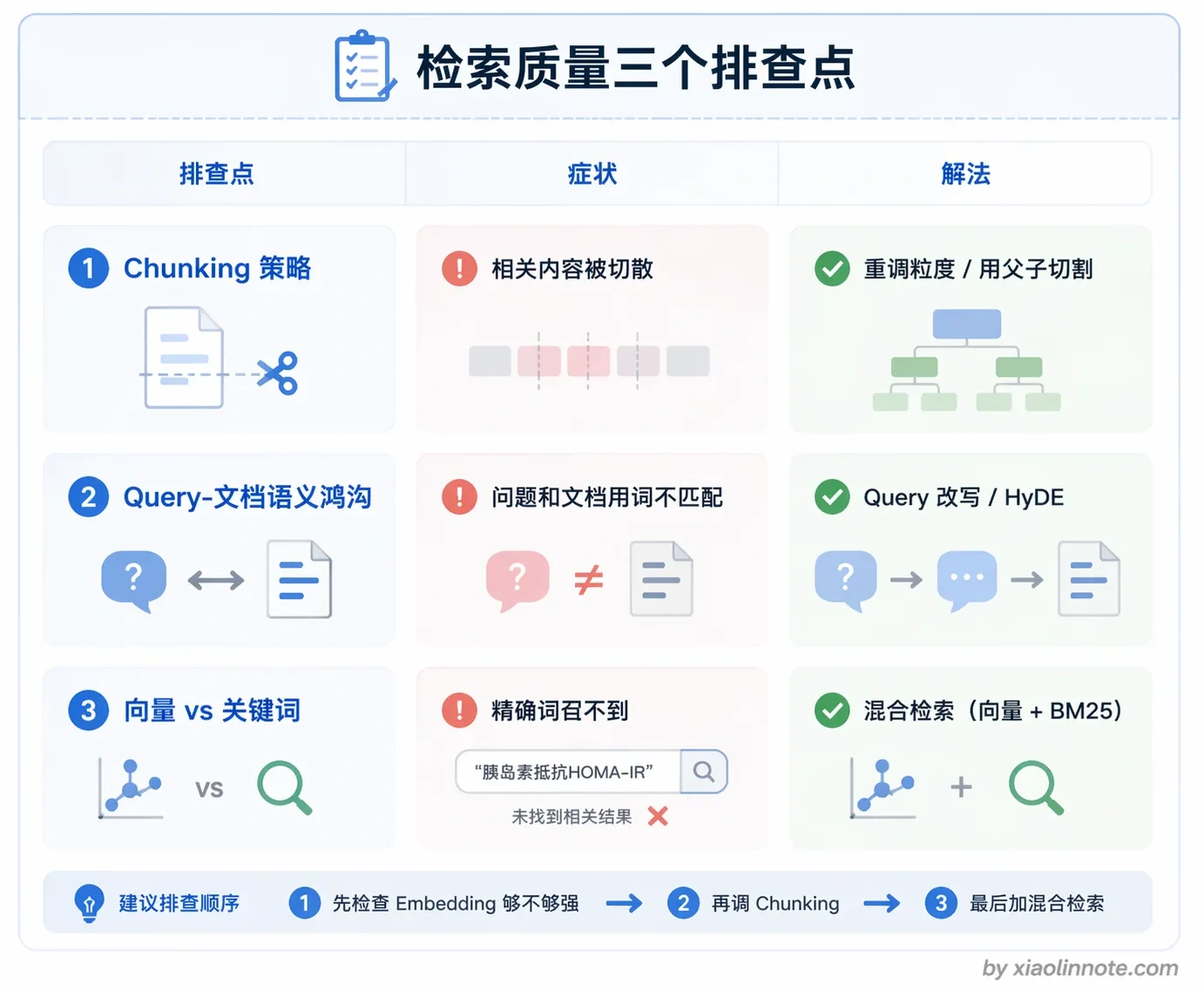
Chunking 策略是第一个排查点。chunk 切得不好,用户问的问题和知识库里的相关内容语义对不上。比如用户问「退款流程是什么」,但知识库里的文档是按产品分类组织的,退款相关的内容被切散在十几个不同的 chunk 里,每个 chunk 单独来看相关度都不高,导致召回的都是些边缘内容。
Query 和文档的语义鸿沟是第二个排查点。用户的提问往往是口语化的,而知识库里的文档是正式的技术或业务语言。比如用户问「这个功能怎么用不了」,文档里的表述是「系统故障排查指南」,向量相似度可能不高,导致正确的文档没被召回。解法是 Query 改写,或者在存文档时也为每个 chunk 生成几个可能的提问形式一起存进去(假设性问题增强)。
还有一个容易忽视的问题:向量检索对精确词语效果差。很多人以为向量检索什么都能搜,其实不是。产品型号「Pro Max 256GB」、专有名词、缩写等,纯向量检索往往不如 BM25 关键词检索。生产环境里通常要做混合检索,向量检索和关键词检索各召回一批,再合并去重,效果比单独用任何一种都好。
第三难:效果评估困难
检索质量调优费劲,但更让人头疼的是:你怎么知道调完之后变好了还是变差了?RAG 系统上线之后,你怎么知道它好不好?这个问题比看起来难得多。
单条答案的对错人工判断成本高,而且不同人的标准不一样。端到端的指标(用户满意度、解决率)反馈周期太长,出了问题不知道是 Chunking 的锅还是检索的锅还是 LLM 生成的锅。
工程上比较实用的做法是把评估拆成两层。
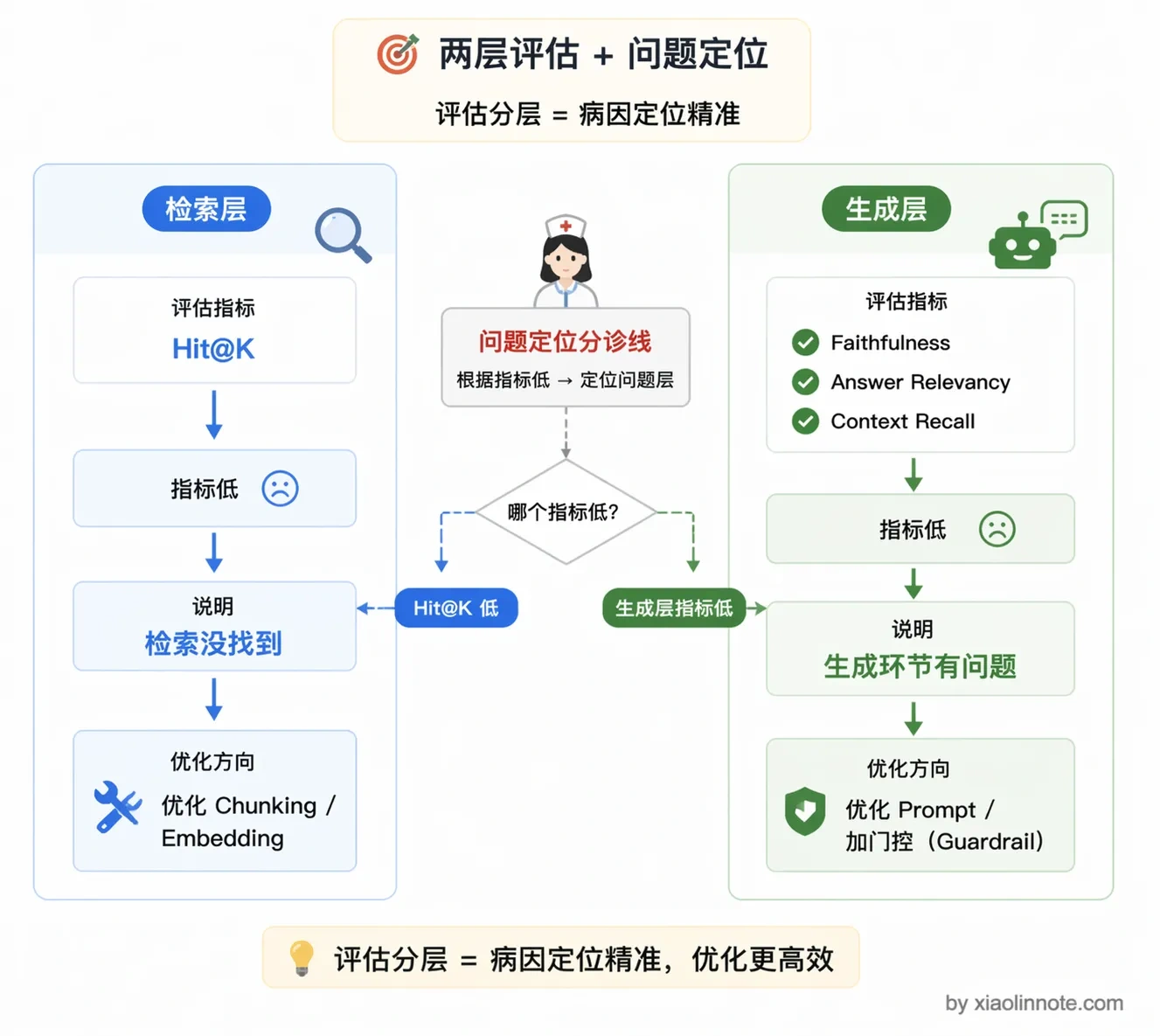
第一层是检索层评估,不管 LLM 的输出,只看「该召回的文档有没有被召回到」。具体用的指标叫 Hit@K:正确答案有没有出现在检索结果的前 K 条里。比如 Hit@5 = 0.8,意思是 80% 的问题,它对应的答案都出现在了前 5 条检索结果里。这个指标可以自动化批量跑,快速定位检索是否是系统瓶颈。
第二层是端到端评估,用 RAGAs 这类框架自动打分。RAGAs 主要评估三个维度。
Faithfulness(忠实度)衡量 LLM 的答案有没有编造知识库里没有的内容,高 Faithfulness 说明模型老老实实在复述检索到的内容,没有瞎编。
Answer Relevancy(答案相关性)看答案和问题是否对应,防止模型「答非所问」。
Context Recall(上下文召回率)看检索出来的内容是否覆盖了回答问题所需的全部知识,这个指标低说明检索层遗漏了关键信息。
三个指标结合起来,基本能定位是检索层的问题还是生成层的问题。
总结来看,RAG 落地最大的感受是:原型 Demo 一两天能跑起来,但把它调到生产可用的质量水平,往往需要几周甚至几个月的迭代。每个环节都可以是瓶颈,文档预处理、Chunking 策略、Embedding 选型、检索方式、Rerank、Prompt 设计,任何一个做得差都会拖累整体效果,而且各环节之间还相互影响,没有捷径。
🎯 面试总结
回到面试官的问题,RAG 落地最难的不是单点技术选型,而是整个链路上每个环节都可能成为瓶颈,而且环环相扣。
系统来说有三大难点。第一是文档预处理,PDF 表格、扫描件、复杂排版解析不好,进去的是垃圾出来的也是垃圾。
第二是检索质量调优,Chunking 策略、语义鸿沟、精确词召回这三个问题交织在一起,排查起来非常费劲。
第三是效果评估,没有量化指标体系就不知道该优化哪里,优化变成了瞎猜。
面试中回答这类问题,关键是要能分层、有体系地说明难点在哪,而不是东一榔头西一棒槌地罗列问题。
对了,大模型面试题会在「公众号@小林面试笔记题」持续更新,林友们赶紧关注起来,别错过最新干货哦!
