Agent 面试题
Agent 面试题
1. 什么是 Agent?与大模型有什么本质不同?
💡 简要回答
我理解 Agent 本质上是一个能自主完成目标的 AI 系统,跟传统 AI 最核心的区别在于「自主性」和「能行动」。传统 AI 是你问一个问题它回答一个问题,每次都是独立的,被动响应;而 Agent 有自己的规划能力,你给它一个复杂目标,它会自己把任务拆成多步,通过调工具、访问记忆、感知环境来一步步执行,直到完成。它不只是输出文字,而是真的能做事。
📝 详细解析
普通大模型的局限性
要理解 Agent,得先说说普通大模型的局限性在哪。
你直接调用 GPT 的 chat 接口,它本质上是个「问答机器」,你给它一个输入,它给你一个输出,然后就结束了。就算是多轮对话,它也只是在当前上下文里被动响应你,它不会主动去做任何事,也不知道自己上一步做了什么、下一步该做什么。你可以把它想象成一个只会答题的人,你说一句它答一句,但让它「自己去查个资料再来汇报你」,它完全做不到。
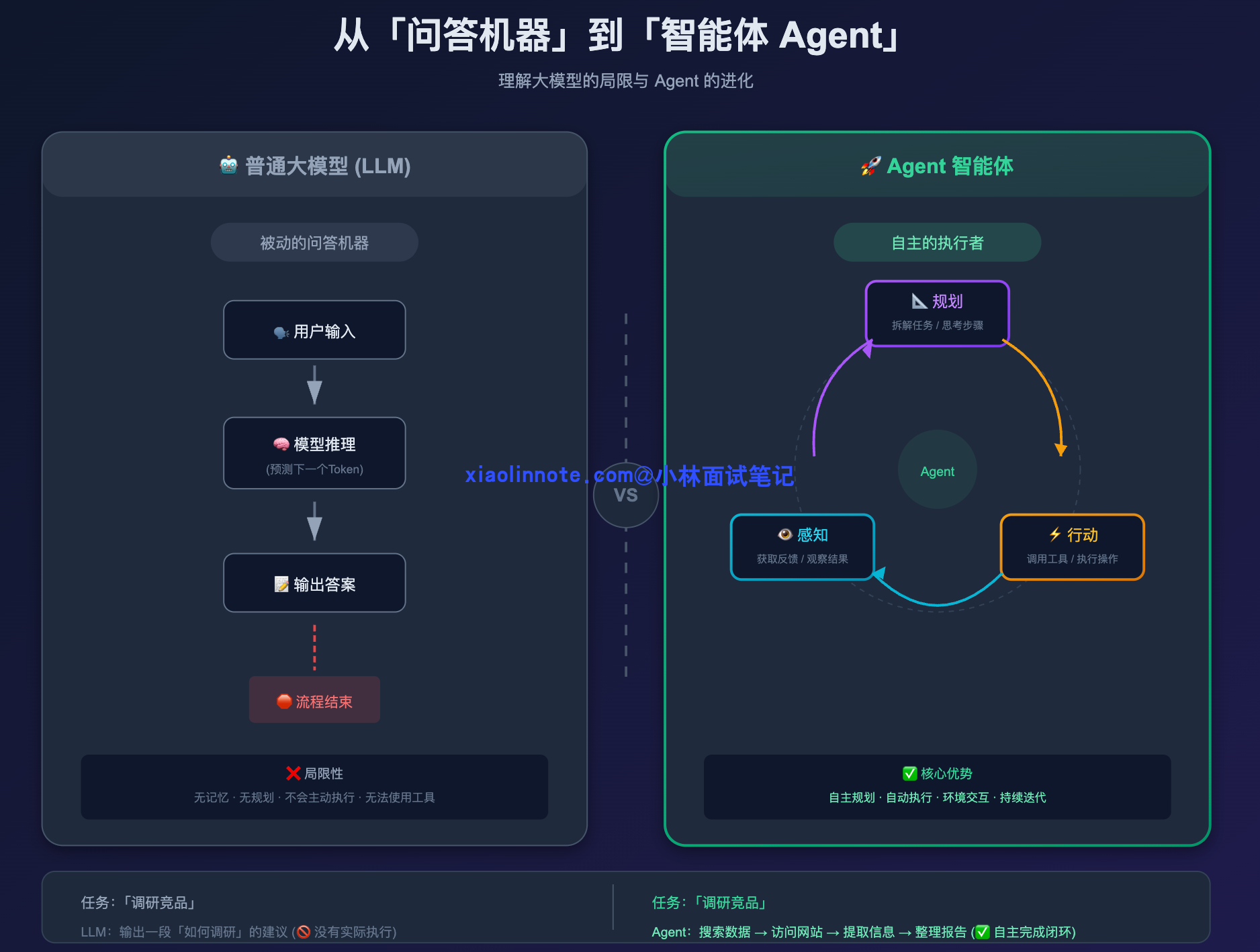
Agent 特别在哪?
Agent 就完全不一样了。它有一个核心的运作闭环:感知 -> 规划 -> 行动 -> 再感知。
你给它一个目标,比如「帮我调研竞品然后整理成报告」,它不是直接输出一段文字了事,而是先拆解任务,我要搜索哪些关键词、我要访问哪些网站、我要怎么组织内容,然后一步一步去执行,每一步的结果又反馈回来,指导下一步怎么做。
这种能力背后,有三件核心的事在支撑,我一个一个讲。
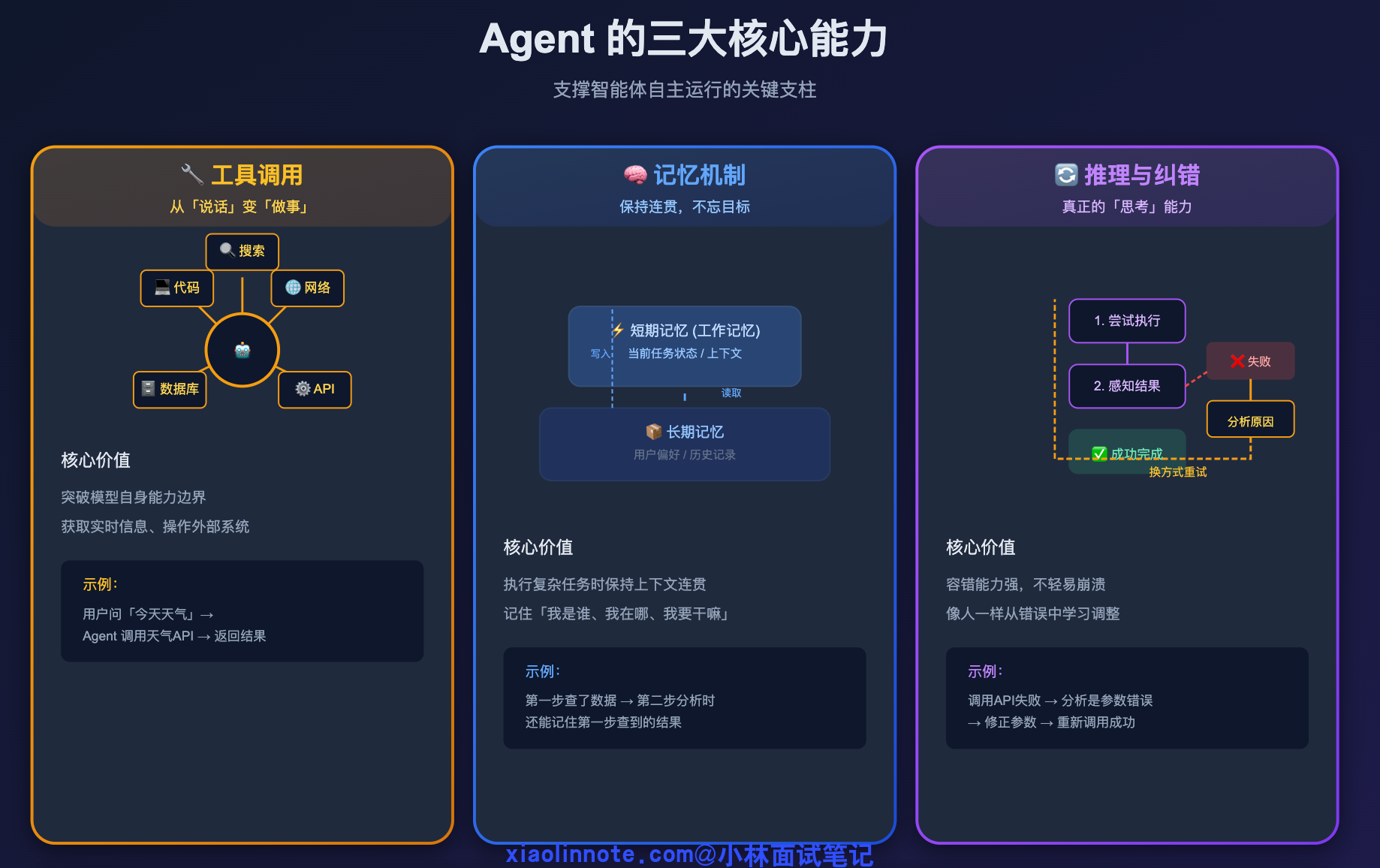
第一件:工具调用(Tool Use),这是让 Agent 从「说话」变成「做事」的关键。Agent 能调用外部工具,比如搜索引擎、代码执行器、数据库、API 等等。不过这里有一个容易误解的地方:不是模型自己执行,而是模型「告诉你该调什么」,你的代码去真正执行,结果再反馈给模型。模型始终只是大脑,不是手脚。
我来举个最具体的例子。假设你给 Agent 配了两个工具:查天气和发邮件,然后让它「帮我查一下北京天气,发邮件给老板」:
# 这里定义了两个工具,就像给 Agent 配了两个「技能说明书」
# 注意:这里没有一行真正执行的逻辑,只是告诉模型「我有哪些能力、需要哪些参数」
tools = [
{
"name": "get_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
},
{
"name": "send_email",
"description": "发送邮件给指定收件人",
"parameters": {
"type": "object",
"properties": {
"to": {"type": "string"},
"subject": {"type": "string"},
"body": {"type": "string"}
},
"required": ["to", "subject", "body"]
}
}
]
# 你告诉 Agent:"帮我查一下北京天气,然后发邮件给 boss@company.com"
# Agent 不是一次性回答,而是分两步真正执行:
# 第一步:调用 get_weather(city="北京") → 得到 "晴天 15°C"
# 第二步:调用 send_email(to="boss@company.com", subject="今日天气", body="北京今天晴天 15°C")
# 每一步都是真实发生的,不是在"假装"你看这段代码,工具定义里没有一行执行逻辑,只有「名字、描述、需要哪些参数」,本质上就是一份说明书。模型读了这份说明书,自己决定该调哪个工具、参数填什么,然后把决策以 JSON 格式告诉你,真正执行的还是你的代码。这个「决策和执行分离」的思想,是理解工具调用最核心的一点。
第二件:记忆机制。传统 LLM 每次对话都是「失忆」的,除非你手动传上下文,不然它完全不记得上一次说了什么。而 Agent 系统通常会设计短期记忆(当前任务的中间状态)和长期记忆(跨任务的用户偏好、历史操作记录),这让它在执行复杂任务时能保持连贯性,不会做到一半忘了目标是什么。
第三件:多步推理和自我纠错。Agent 在执行过程中如果某一步失败了,能感知到失败、分析原因、换一种方式重试,而不是直接崩掉。这就像一个真正在「思考」的执行者,而不是一个只会背答案的系统。
讲完这三件事,我们用一个最直观的场景来感受一下差距。你让一个普通 LLM「帮我发一封天气播报邮件」,它能做的只是告诉你「你可以这样写代码……」;而一个 Agent,它会真的去调天气 API、拿到数据、组织邮件内容、再调邮件发送接口,整个过程自动完成。这就是本质区别:从生成文字,到执行任务。
2. Agent 的基本架构由哪些核心组件构成?
💡 简要回答
我理解 Agent 的基本架构有四个核心组件:LLM、工具、记忆、规划模块。LLM 是整个系统的大脑,负责理解任务和做决策;工具让 Agent 能跟外部世界交互,搜索、执行代码、调 API 都靠它;记忆让 Agent 在任务执行过程中保持状态,不会「失忆」;规划模块负责把复杂目标拆解成可执行的步骤。这四个组合在一起,才让 Agent 具备了自主完成任务的能力。
📝 详细解析
理解了 Agent 是什么之后,我们来看它的内部结构,一个完整的 Agent 系统,到底由哪几个核心部件组成。
你可以把整个 Agent 系统类比成一家公司:LLM 是老板,所有决策都经过它拍板;工具系统是外包执行团队,老板说「去搜这个」「去发这封邮件」,他们负责真正干活;记忆系统是公司档案室,各种信息的存档和调档都靠它;规划模块是项目经理,拿到一个大目标后负责拆解成可执行的任务单。四个角色各司其职,才撑起了 Agent 的自主运行能力。
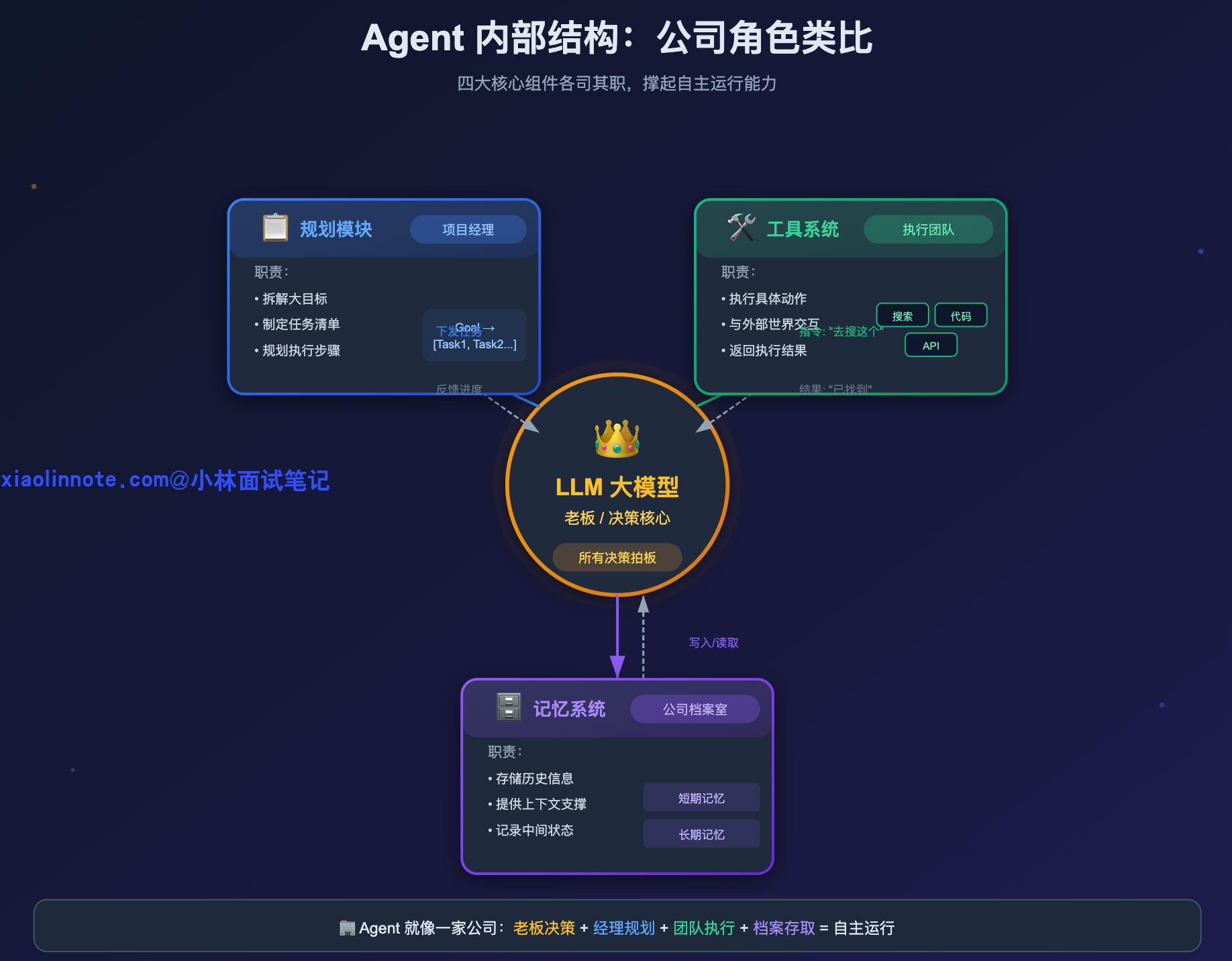
先来说 LLM 核心。它是整个 Agent 的大脑,所有的输入,不管是用户的指令、工具返回的结果还是记忆里调出来的内容,最终都要经过 LLM 来理解和决策。它负责判断:下一步该做什么?是继续思考、调用某个工具、还是已经可以给出最终答案了?没有 LLM,其他三个组件就是一堆零件,没有人来统一指挥。
然后是 工具系统,这是 Agent 和外部世界交互的唯一入口。LLM 本身是个纯粹的「语言处理器」,它不能上网、不能读文件、不能执行代码,但这些限制都可以通过工具来突破。工具可以是搜索引擎、数据库查询、代码执行器、发邮件的 API,任何你能用函数封装的能力都可以变成工具。
工具是怎么定义的?我给你看一个最标准的格式:
# 定义工具的结构(以 OpenAI function calling 格式为例)
# 你只需要告诉模型三件事:工具叫什么名、能做什么事、需要哪些参数
tools = [
{
"type": "function",
"function": {
"name": "search_web",
"description": "搜索互联网上的信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
}
},
"required": ["query"]
}
}
}
]
# LLM 决定调用工具时,会返回类似这样的结构:
# {"tool_call": {"name": "search_web", "arguments": {"query": "2024年大模型最新进展"}}}
# 然后你的代码负责真正执行这个搜索,把结果再塞回给 LLM你看,工具定义里没有一行执行逻辑,只有「名字、描述、参数说明」。模型读了这份说明书,决定要调哪个工具、参数填什么,把决策以 JSON 格式告诉你,你的代码去真正执行,结果再反馈给模型。整个分工很清晰:模型负责「决定做什么」,程序负责「真正执行」。
接下来是 记忆系统,它分两层,你可以类比人的记忆方式来理解。短期记忆就是当前这轮对话的上下文,装在 context window 里,Agent 在一次任务执行过程中靠它记住中间状态,比如第一步搜索到了什么、第二步执行结果是什么。这就像人的「工作记忆」,容量有限,任务一结束就清空了。所以还需要长期记忆,通常用向量数据库来实现,把重要信息 embedding 之后存起来,下次用的时候做语义检索拿回来。这就像人的「长期记忆」,容量大、可以跨天保留,但需要主动「回忆」才能调出来。
最后是 规划模块,它决定了 Agent 能不能应对复杂任务。简单任务一步就搞定了,但如果你让 Agent「帮我写一份竞品分析报告」,它需要先把这个目标拆解:搜索竞品资料 -> 整理关键数据 -> 对比分析 -> 撰写报告。规划模块就是做这件事的,有些实现是让 LLM 先输出一个完整计划再逐步执行,有些是边执行边规划,根据每步结果动态调整。
这四个组件合在一起,到底是怎么跑起来的?我用一段伪代码来还原整个运行过程,看完你就能理解它们是怎么协作的:
# Agent 运行的核心 loop(伪代码)
def agent_run(user_goal: str):
# 第一步:规划模块上场,把目标拆成步骤列表
plan = llm.plan(user_goal)
memory = [] # 短期记忆,用来存每一步的中间结果
for step in plan:
# 第二步:LLM 核心做决策,这一步该怎么做?
action = llm.decide(
step=step,
history=memory, # 把短期记忆传进去,让它知道之前做了什么
long_term=vector_db.search(step) # 从长期记忆里捞出相关历史
)
if action.type == "tool_call":
# 第三步:工具系统负责真正执行
result = tools.execute(action.tool_name, action.args)
memory.append({"step": step, "result": result}) # 执行结果存入短期记忆
elif action.type == "final_answer":
return action.content # LLM 判断任务完成,返回最终答案看完这段伪代码,你会发现 Agent 的核心节奏其实很简单:规划 -> 决策 -> 执行 -> 结果存入记忆 -> 再决策,循环往复,直到任务完成。LLM 始终是那个做决策的角色,工具系统是执行者,记忆系统让它不会「失忆」,规划模块帮它把大目标拆成小步骤。
LangChain、LlamaIndex、AutoGen 这些主流框架,本质上都是围绕这四个组件来设计的,只是封装方式和侧重点各有不同。
3. 了解哪些其他的 Agent 设计范式?Agent 和 Workflow(工作流)的区别是什么?
💡 简要回答
我理解 Agent 和 Workflow 最核心的区别是「谁来决定下一步」。Workflow 是我提前把流程写死的,每一步怎么走都是固定的,确定性高、好控制;Agent 是让 LLM 自己决定下一步做什么,灵活但不可控。常见的设计范式除了纯 Agent 之外,还有 ReAct、Plan-and-Execute、Reflection 这几种。我在实际工程里用得最多的反而是把两者混用,固定流程的部分用 Workflow,需要灵活决策的节点嵌入 Agent 能力,这样既保住了整体可控,又有局部的灵活性。
📝 详细解析
在 Agent 开发里有一个非常基础但经常被忽视的问题:什么情况下该用 Agent,什么情况下该用 Workflow? 这是实际工程里最常碰到的架构决策,弄错了要么过度工程化,要么系统一点都不可控。
先把两者的本质区别说清楚。Workflow 就是一个确定性的流程图,你提前定好「第一步做 A,A 完了做 B,B 失败了走分支 C」,每一步的逻辑都是你硬编码进去的,LLM 只是其中某个节点的执行工具,不负责决策流程本身。好处是行为完全可预测、容易测试、出了问题好排查;坏处是灵活性低,遇到你没预料到的情况就会走入死胡同。
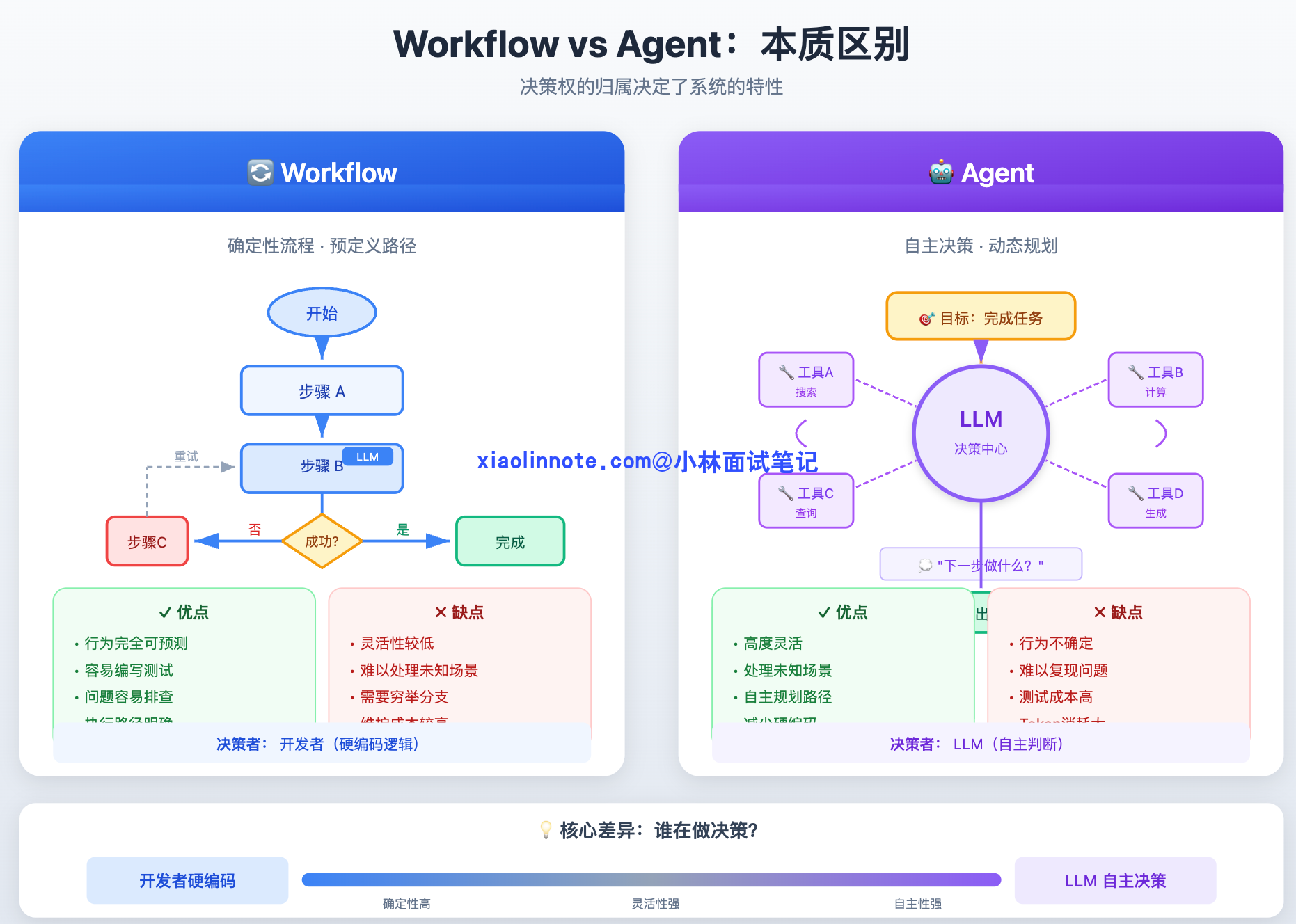
Agent 则相反,它把「下一步做什么」这个决策权交给了 LLM。你只告诉它目标,它自己判断该调哪个工具、该不该继续、什么时候算完成。好处是能处理你事先没设计进去的情况;坏处是行为不确定,同样的输入可能走出不同的路径,线上出了问题也很难复现。
光说文字可能还不够直观,我用代码结构来对比一下,你一眼就能感受到区别:
# Workflow 风格:流程固定,每步都是确定的,LLM 只是工具
def workflow_answer_question(user_query: str):
# 第一步:固定做向量检索
docs = vector_db.search(user_query, top_k=5)
# 第二步:固定做 rerank(重排序,筛选最相关的结果)
reranked = reranker.rank(user_query, docs)
# 第三步:固定喂给 LLM 生成答案
answer = llm.generate(user_query, context=reranked)
return answer
# Agent 风格:流程不固定,LLM 自己在运行时动态决定每一步
def agent_answer_question(user_query: str):
while True:
# LLM 自己决定:要搜索?要计算?还是直接回答?
action = llm.decide(user_query, history=memory)
if action.type == "search":
result = vector_db.search(action.query)
memory.append(result)
elif action.type == "calculate":
result = calculator.run(action.expr)
memory.append(result)
elif action.type == "final_answer":
return action.content对比来看,Workflow 的每一行都是明确的指令,控制流完全由代码决定;Agent 的 loop 里只有 llm.decide(),所有路径都是 LLM 在运行时动态选的。两种风格在代码结构上就完全不一样,Workflow 是「开发者在驾驶」,Agent 是「LLM 在驾驶,开发者在副驾驶设了一些安全限制」。
在具体的 Agent 设计范式上,目前主流的有这几种:
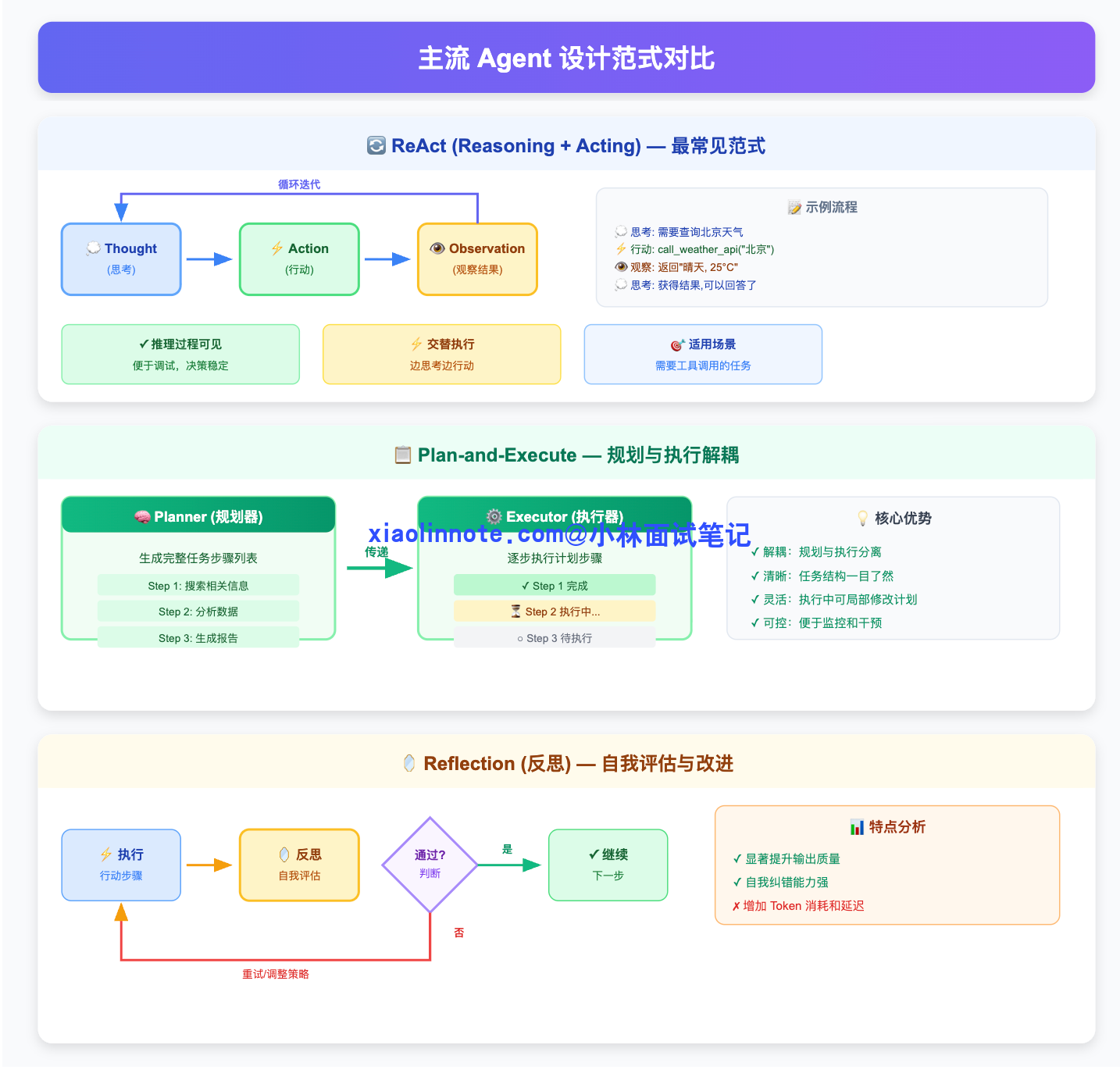
ReAct(Reasoning + Acting)是最常见的一种。它让 LLM 交替输出「思考」和「行动」,每次行动前先写出推理过程,行动后再根据结果继续思考。好处是推理过程可见,便于调试,决策也更稳定。
Plan-and-Execute 是把规划和执行分开的范式。先让一个 LLM 专门做规划,输出完整的任务步骤列表;再让另一个 LLM 或模块逐步执行。规划和执行解耦之后,复杂任务的整体结构更清晰,也方便在执行过程中对计划做局部修改。
Reflection(反思) 是在 Agent 完成一步之后,加一个自我评估的环节,让 LLM 判断这步做得对不对、结果是否符合预期,不行就重试或者调整策略。这能显著提升输出质量,但也会增加 token 消耗和延迟。
实际工程里,纯 Agent 模式其实用得不多,因为太难控制。
更常见的做法是**「Agentic Workflow」**,整体用 Workflow 框住主流程,在需要灵活处理的节点嵌入 Agent 能力。比如一个客服系统,意图识别 -> 知识检索 -> 回答生成这条主链路是固定的 Workflow,但「知识检索」这个节点内部可以用 Agent 来动态决定检索几轮、用哪些工具。这样既保住了整体可控,又有局部的灵活性,这是目前生产环境里最主流的做法。
两种模式的核心差异,直接对照看更直观:
| 维度 | Workflow | Agent |
|---|---|---|
| 决策者 | 开发者(硬编码流程) | LLM(动态决策) |
| 确定性 | 高,行为完全可预测 | 低,同输入可能走不同路径 |
| 灵活性 | 低,流程固定 | 高,能处理预料之外的情况 |
| 调试难度 | 容易,链路清晰 | 困难,行为不确定 |
| 适用场景 | 流程相对固定的业务 | 需要灵活判断的复杂任务 |
4. Workflow,Agent,Tools 这三个的概念和区别介绍一下?
💡 简要回答
我理解这三个概念是粒度从小到大的三层结构。Tools 是最小的能力单元,就是封装好的可调用函数,比如搜索、执行代码、发邮件,它只负责「执行」,本身没有任何决策能力;Agent 是一个完整的决策系统,内部用 LLM 做大脑,自己判断什么时候调哪个 Tool、要不要继续、什么时候结束,是主动的;Workflow 是更上层的编排框架,把 Agent、LLM、Tools 组织成一条确定性流程,每个节点做什么、按什么顺序流转都是开发者事先写死的。三者最核心的区别就一句话:Tools 不做决策只执行,Agent 自己做决策,Workflow 是开发者替所有节点把决策提前写好。
📝 详细解析
要理解这三个概念,得先搞清楚一件事:它们根本不是同一维度的东西,而是粒度不同、可以相互嵌套的三层结构。 很多文章把它们并排列出来对比,容易让人误以为是三选一的关系,其实不是。你在做实际项目的时候,三者通常同时存在,只是扮演不同的角色。
我们按从小到大的粒度,一层一层讲清楚。
第一层:Tools,最小的能力积木
Tools 是整个体系里最简单、最底层的概念,它就是一个封装好的函数,有明确的输入参数、明确的输出结果,就这么简单。
你给 LLM 配备的每一个能力,比如「查天气」「搜索网页」「执行 Python 代码」「往数据库写一条记录」,本质上都是一个函数。Tools 和普通函数唯一的区别是:你需要额外写一份「说明书」告诉 LLM 这个工具叫什么名字、能做什么事、需要传哪些参数,这样 LLM 才知道自己有哪些能力可以调用。
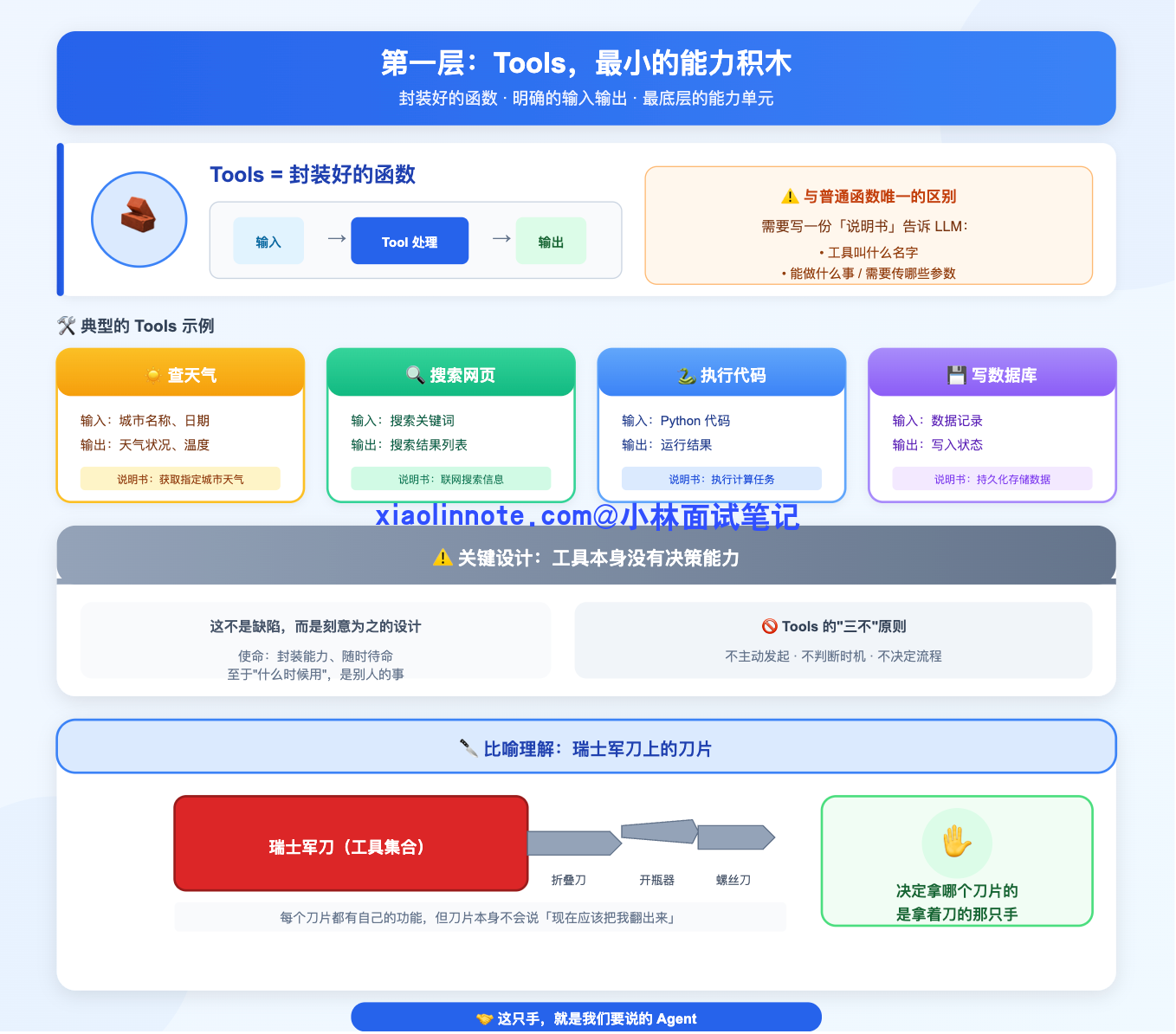
来看一个最直观的例子:
# 定义两个工具,注意观察:这里只有「说明书」,没有任何决策逻辑
# Tools 根本不知道自己「应该」在什么时候被用,它只负责「被调用时干什么」
tools = [
{
"name": "web_search",
"description": "在互联网上搜索信息,适合查询实时数据或不确定的知识",
"parameters": {
"type": "object",
"properties": {
# 参数说明清晰,LLM 看到这个描述就知道该填什么
"query": {"type": "string", "description": "搜索关键词,越具体越好"}
},
"required": ["query"]
}
},
{
"name": "send_email",
"description": "向指定邮箱发送一封邮件",
"parameters": {
"type": "object",
"properties": {
"to": {"type": "string", "description": "收件人邮箱地址"},
"subject": {"type": "string", "description": "邮件主题"},
"body": {"type": "string", "description": "邮件正文内容"}
},
"required": ["to", "subject", "body"]
}
}
]
# 工具的实际执行逻辑单独写,和「说明书」是分开的
def execute_web_search(query: str) -> str:
# 这里才是真正发出 HTTP 请求去搜索的代码
...
def execute_send_email(to: str, subject: str, body: str) -> str:
# 这里才是真正调用邮件 API 发送邮件的代码
...注意一个很关键的设计:工具本身没有任何决策能力,它甚至不知道自己「应该」在什么时候被使用。 这不是什么设计缺陷,而是故意的,Tools 的使命就是把一个具体能力封装好、随时待命,至于什么时候该用它,那是别人的事。
你可以把 Tools 理解成瑞士军刀上的每一个刀片:折叠刀、开瓶器、螺丝刀,每个刀片都有自己擅长的事,但刀片本身不会说「现在应该把我翻出来」。决定拿哪个刀片的,是拿着刀的那只手。 这只手,就是我们接下来要说的 Agent。
第二层:Agent,拿着工具自己做决定的人
理解了 Tools 之后,Agent 就很好懂了。Agent 就是那个「拿着工具、自己决定用哪个」的角色。
你给 Agent 一个目标,比如「帮我调研一下最近竞品的动态」,它不会直接给你一个答案,而是开始自己思考:我要完成这个目标,第一步应该搜索什么关键词?搜索结果里有没有我需要的信息?需不需要再多搜几次?什么时候才算调研完了?
这一系列「要不要、用哪个、够不够、停不停」的判断,全部由 Agent 内部的 LLM 做决策。这就是 Agent 和 Tools 最本质的区别:Tools 被动等待调用,Agent 主动做决策。
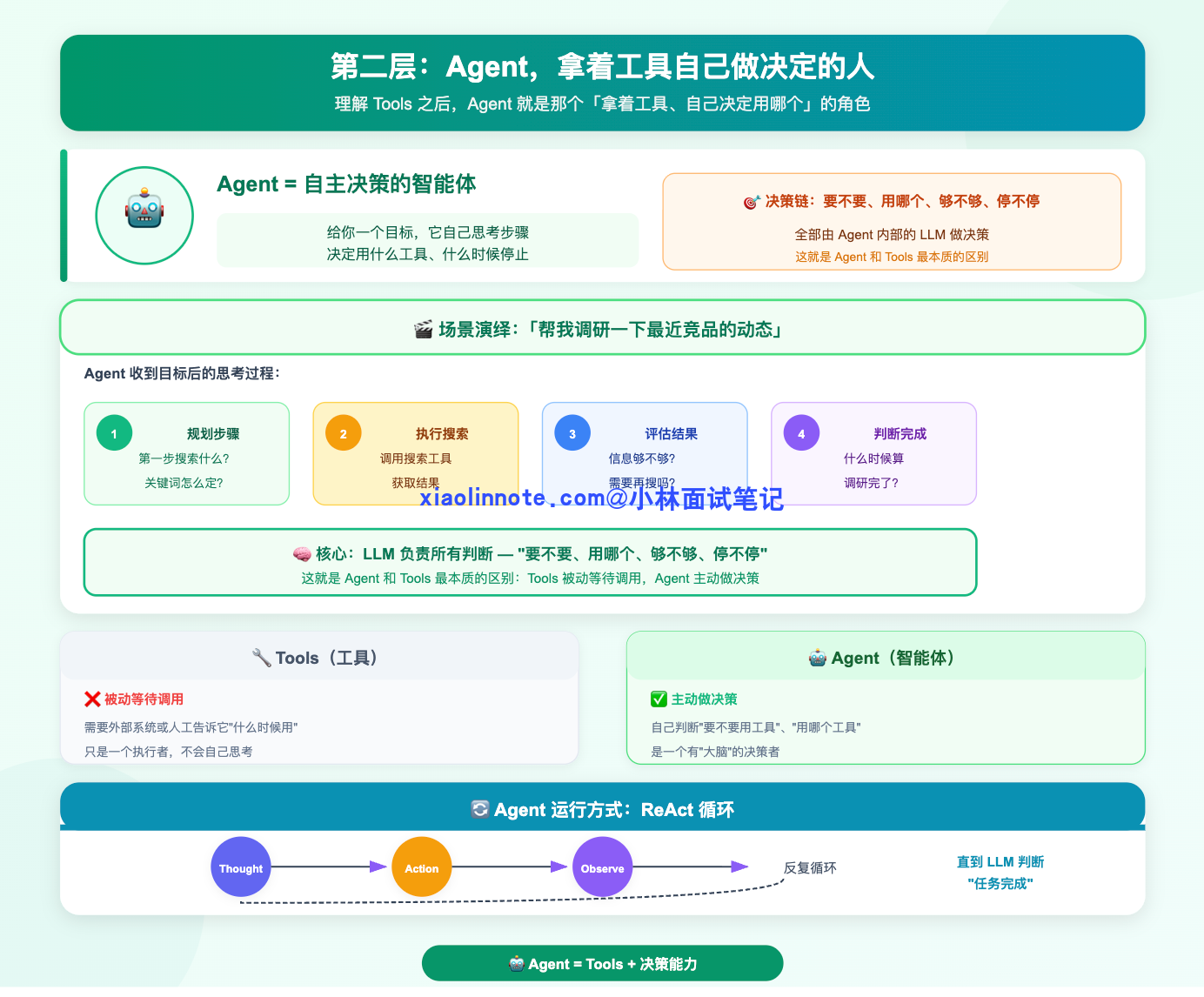
Agent 的运行方式是一个反复循环的过程:想清楚(Thought)-> 行动(Action)-> 看结果(Observation)-> 再想清楚 -> 再行动…… 直到 LLM 判断任务完成为止,这个循环才结束。
用代码来看这个循环是什么样的:
import anthropic
client = anthropic.Anthropic()
def run_agent(user_goal: str):
# 把用户目标放进对话历史,Agent 的所有思考和行动都在这个 messages 里积累
messages = [{"role": "user", "content": user_goal}]
# Agent 的核心:一个不断循环的决策过程
# 注意:开发者根本不知道这个循环会跑几次,完全由 LLM 自己决定
while True:
# 每一轮,LLM 看到当前的完整对话历史,自己判断下一步该做什么
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
tools=tools, # 把「工具说明书」传给 LLM,让它知道自己有哪些能力
messages=messages
)
# LLM 告诉我们「任务完成了」,把最终答案返回出去,循环结束
if response.stop_reason == "end_turn":
return response.content[0].text
# LLM 认为还需要调工具,我们就真正去执行它指定的工具
# 注意:LLM 只是「告诉我们调哪个工具、传什么参数」,真正执行的是我们的代码
tool_use = next(b for b in response.content if b.type == "tool_use")
tool_result = execute_tool(tool_use.name, tool_use.input)
# 把工具的执行结果塞回对话历史,LLM 下一轮能看到这个结果,再接着决策
messages.append({"role": "assistant", "content": response.content})
messages.append({
"role": "user",
"content": [{"type": "tool_result", "tool_use_id": tool_use.id, "content": tool_result}]
})
# 回到循环顶部,LLM 再看一遍现在的状态,做下一步决策这段代码里有一个地方值得特别注意:这个 while True 循环会跑几次,开发者完全不知道,也不需要知道,这正是 Agent 和普通代码最不一样的地方。普通代码的每一步都是开发者预先写好的,但 Agent 的执行路径是 LLM 实时决定的,你可以让它完成复杂的、你事先根本没法预测路径的任务。
当然,这也带来了一个副作用:Agent 的行为是不确定的。同样的任务,今天跑和明天跑,可能调了不同的工具、走了不同的路径,甚至得到微妙不同的结果。这是因为 LLM 本质上是个概率模型,每次生成都带有随机性。灵活性和不确定性是一对孪生兄弟,有 Agent 的灵活,就必然伴随着一定程度的不可预测。
第三层:Workflow,把所有人组织起来的总指挥
理解了 Tools 和 Agent 之后,Workflow 就水到渠成了。
假设你现在要做一个客服系统,大致流程是:先判断用户问的是什么类型的问题,再去知识库里检索相关内容,最后生成一个回答。这里面每一步的逻辑,开发者其实心里都很清楚,先做什么、后做什么、结果满足什么条件走哪个分支,完全可以在代码里写死。
这就是 Workflow 做的事:把整个执行流程的「骨架」写在代码里,LLM、Agent、Tools 都只是这个流程里的「节点」,每个节点负责完成自己那一步,但整体走哪条路、下一步去哪里,全由开发者的代码决定,不是任何节点自己说了算。
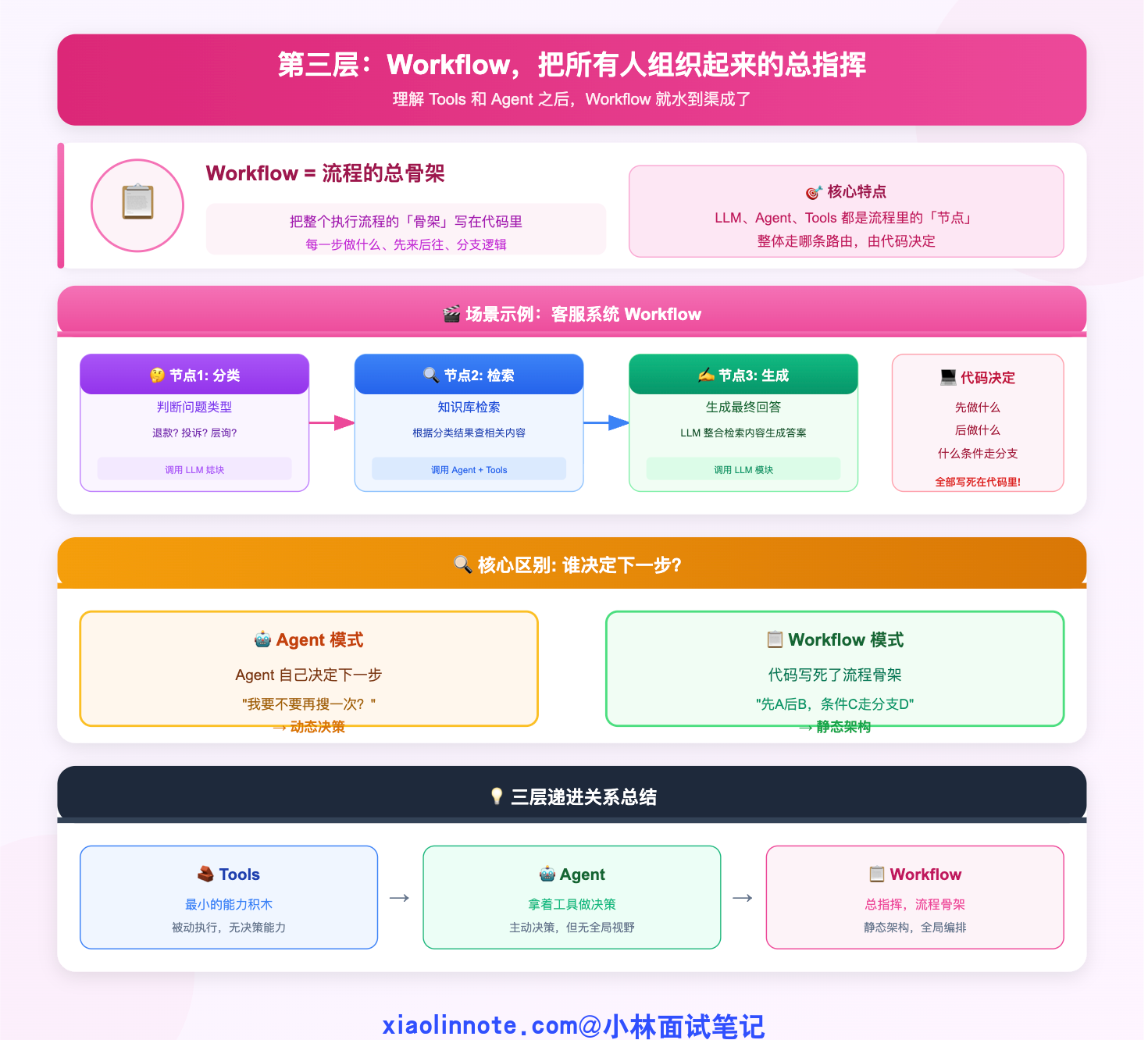
来看一个具体的例子:
def run_customer_service_workflow(user_query: str) -> str:
# ---- 第一步:意图识别 ----
# 这里把 LLM 当成一个分类器来用,它只负责判断这个问题属于哪个类别
# 「下一步去哪」这个决策是下面的 if/elif 来做的,不是 LLM 自己决定的
intent = classify_intent_with_llm(user_query) # 返回 "product" / "refund" / "other"
# ---- 第二步:根据意图走不同分支 ----
# 注意:这个分支判断是开发者写的 Python 代码,不是 LLM 的决策
if intent == "product":
# 产品问题:去知识库检索,再生成回答
docs = search_knowledge_base(user_query) # 直接调 Tool,固定的检索步骤
answer = generate_answer_with_llm(user_query, docs) # LLM 作为节点生成回答
return answer
elif intent == "refund":
# 退款问题:查订单系统,再走审核流程
order_info = query_order_system(user_query) # 调 Tool 查订单
if order_info["eligible"]:
process_refund(order_info["order_id"]) # 调 Tool 处理退款
return "退款已受理,预计 3 个工作日到账"
else:
return "很抱歉,该订单不满足退款条件"
else:
# 其他问题:转人工
escalate_to_human_agent(user_query)
return "已为您转接人工客服,请稍候"
# 整个流程的走向在代码里一目了然
# 出了任何问题,你可以精确定位是哪一步出了错你看,LLM 在这里面出现了两次,一次是做意图分类,一次是生成回答,但它只是流程里的两个工位,「接下来去哪」这件事完全由 if/elif 这些普通 Python 代码控制。这就是 Workflow 和 Agent 最核心的区别:谁在做「下一步去哪」这个决策?Agent 是 LLM 自己决定,Workflow 是开发者在代码里写死。
Workflow 最大的优点是可预测、可控、好调试。你在代码里看到什么,它就做什么,不会有任何「惊喜」。生产环境里出了问题,你可以打断点逐步追,精确定位是哪个节点出了故障。这种确定性在线上系统里非常珍贵。
三者怎么组合?Agentic Workflow 才是生产主流
讲完了三层结构,我们来说说实际工程里怎么用。
很多人学完这三个概念之后,会自然而然地想:「那我应该用哪个?」这个问题本身就有点问错方向了,因为在真实的项目里,三者通常是同时存在、相互嵌套的:
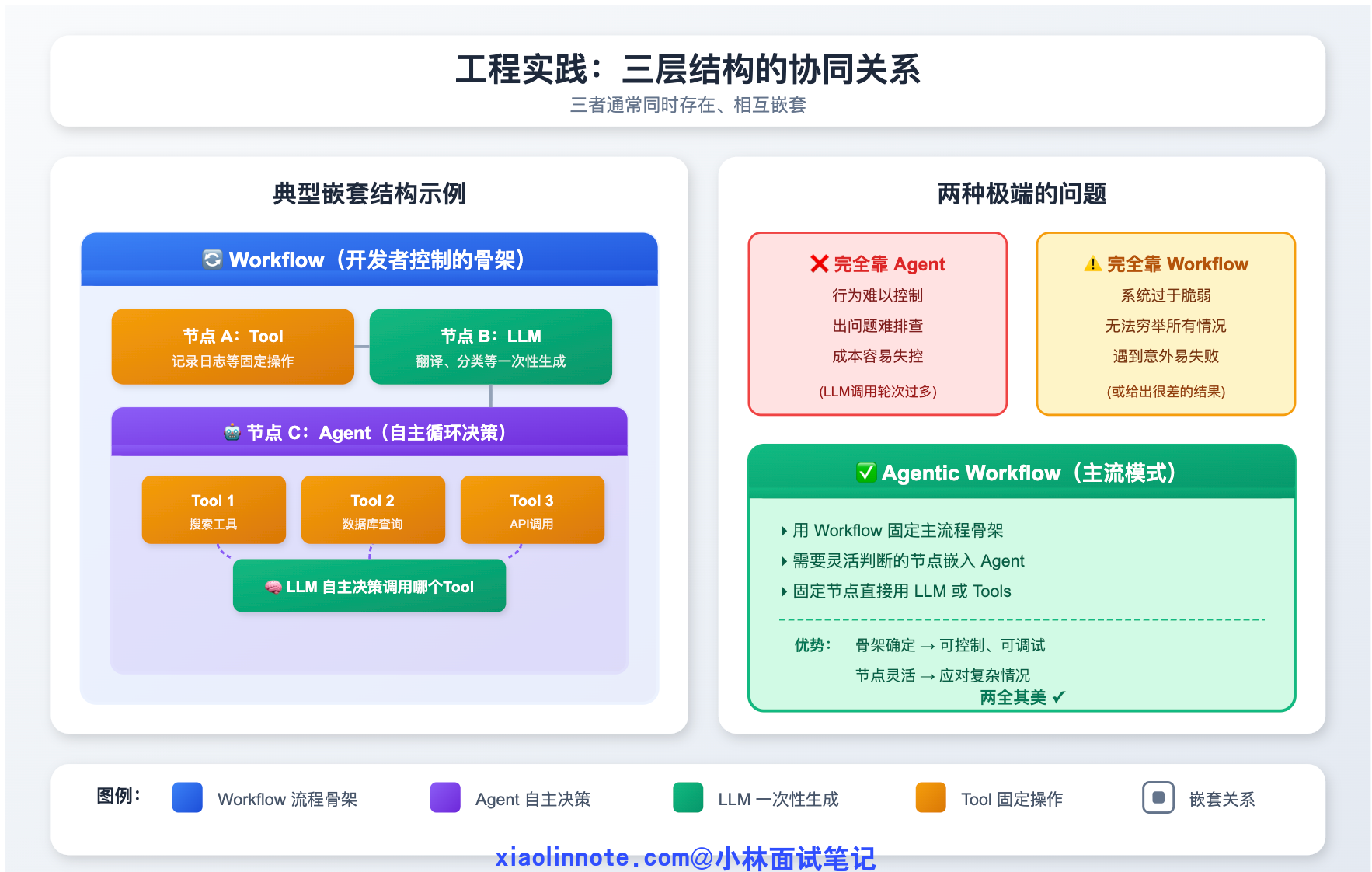
完全靠 Agent 自主决策 的系统其实很少在生产环境里出现,原因很现实:行为太难控制,一旦出问题很难排查,成本也容易失控(LLM 调太多轮)。
完全靠 Workflow 写死 的系统又太脆,因为你没法把所有情况都穷举到代码里,遇到预料之外的输入就容易失败或者给出很差的结果。
所以目前生产环境里最主流的模式是**「Agentic Workflow」**:用 Workflow 固定主流程的骨架,在需要灵活判断的节点嵌入 Agent,其余固定节点直接用 LLM 或 Tools。 骨架是确定的,让你能控制整体行为、便于调试;关键节点是灵活的,让你能应对各种复杂情况。两个优点都有,两个缺点都被削弱了。
把三者的核心差异对照起来看,就很清楚了:
| 维度 | Tools | Agent | Workflow |
|---|---|---|---|
| 决策能力 | 无(只执行,不决策) | 有(LLM 自主动态决策) | 无(开发者在代码里写死) |
| 执行方式 | 被动,等待被调用 | 主动,自主循环直到完成 | 按开发者定义的顺序执行 |
| 确定性 | 高(输入固定则输出固定) | 低(同输入可能走不同路径) | 高(行为完全可预测) |
| 灵活性 | 只做一件事 | 高(能应对预料之外的情况) | 低(流程提前写死,难以动态调整) |
| 调试难度 | 容易(单一函数) | 难(执行路径不确定) | 容易(链路清晰,可逐步追踪) |
| 适用场景 | 封装单一具体能力 | 路径未知的复杂任务 | 流程相对固定的业务系统 |
5. Agent 推理模式有哪些?ReAct 是啥?具体是怎么实现的?
💡 简要回答
Agent 的推理模式我用过几种。最基础的是直接输出答案,没有中间推理;CoT 是让 LLM 先把推理过程写出来再给答案,准确率更高;ReAct 是在 CoT 基础上加了「行动」,让 LLM 交替输出思考和工具调用,每次行动后再根据结果继续思考,形成一个循环。我觉得 ReAct 是目前 Agent 用得最广的模式,因为它推理过程可见,又能动态利用外部工具,两个优点都有。
📝 详细解析
什么是推理模式?
要理解「推理模式」这个词,得先说清楚 LLM 面临的一个根本困境。
LLM 的工作原理,是根据你给它的输入,一个 token 一个 token 地往后预测。

你问它一个简单问题,它可以直接说出答案。但如果你问的是一个需要多步推导的问题,比如「A 公司的市值是 B 公司的 1.2 倍,B 公司比 C 公司高 30%,请问 A 和 C 谁更高,差多少?」,LLM 在没有任何辅助的情况下,往往直接给你一个「感觉对」的答案,而这个答案可能是错的。原因在于,当它「一口气」预测答案时,中间的推导步骤都是隐式的,没有办法强制自己在每一步都做出正确的推断。误差会在中间某个暗处悄悄累积,最终暴露在答案里。
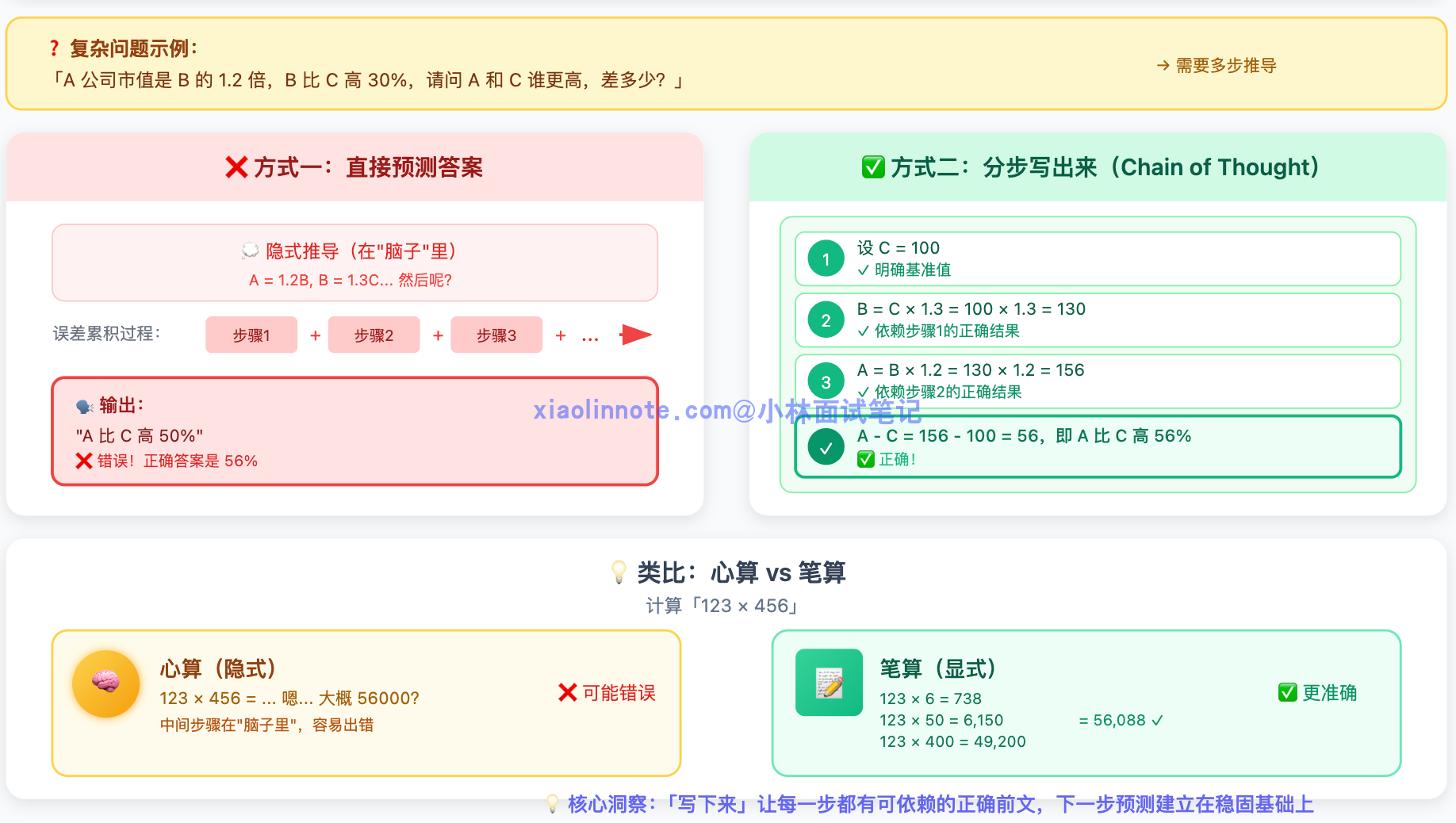
你可以把它类比成心算和笔算的区别。让你心算「123 × 456」,你可能算错;但如果你把每一步都写在纸上,「123 × 6 = 738、123 × 50 = 6150……」,一步一步来,算错的概率就会大大降低。原因不是你突然变聪明了,而是「写下来的过程」本身帮助你避免在中间某步跳跃出错。LLM 也一样,把推导过程写出来,就等于在每一步都有了一个可以依赖的「前文」,下一步的预测建立在一个已经写清楚的正确基础之上。
「推理模式」存在的根本原因就是这个:通过不同的方式,让 LLM 把隐式的思考过程显式化出来,从而减少多步推理中的累积误差。CoT、ReAct 就是这个方向上的两种解法,每一个都在解决前一个的局限性。
CoT是什么?
CoT,全称 Chain of Thought(思维链),是最早也最简单的解法。
核心想法极其朴素:在 prompt 里加一句「让我们一步步思考」,LLM 就会先把推理步骤写出来,再给答案,而不是直接蹦出结论。为什么加一句话就有效?
本质是因为 LLM 的输出是顺序生成的,先写出来的推理内容会进入上下文,成为后续生成的依据。
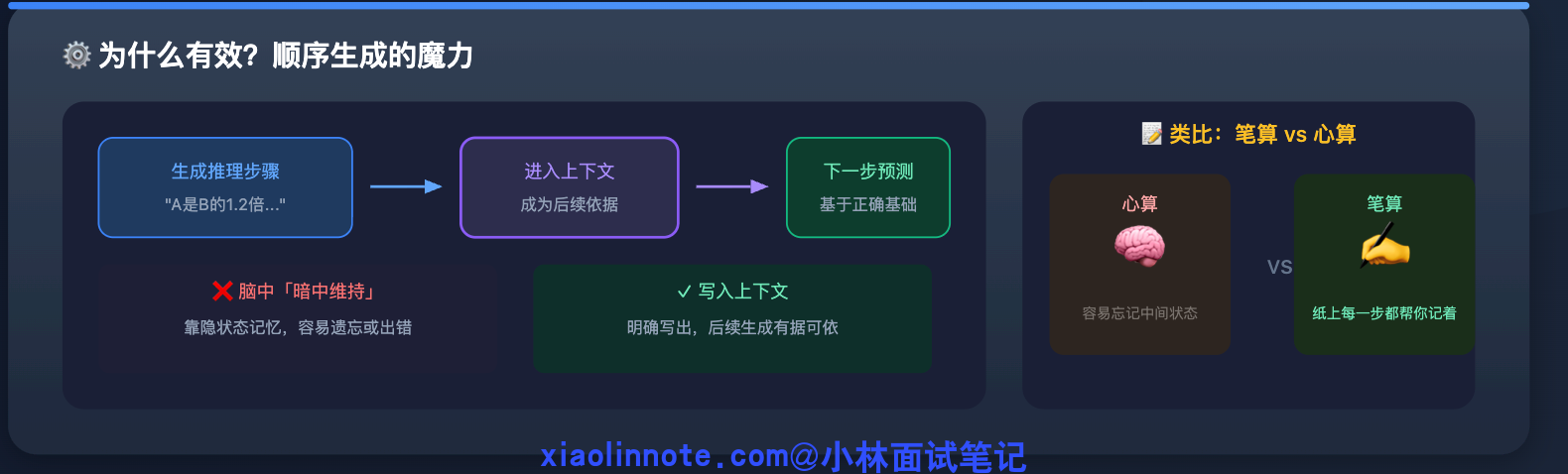
当 LLM 先写出「第一步:A 市值是 B 的 1.2 倍,所以 A > B」这句话之后,这个推导结论就进入了上下文,下一步的预测建立在这个明确写出的正确基础上,而不是靠它在脑子里「暗中维持」这个中间状态。就像笔算,纸上的每一行数字都在帮你记住上一步算到哪了。
CoT 有两种触发方式。
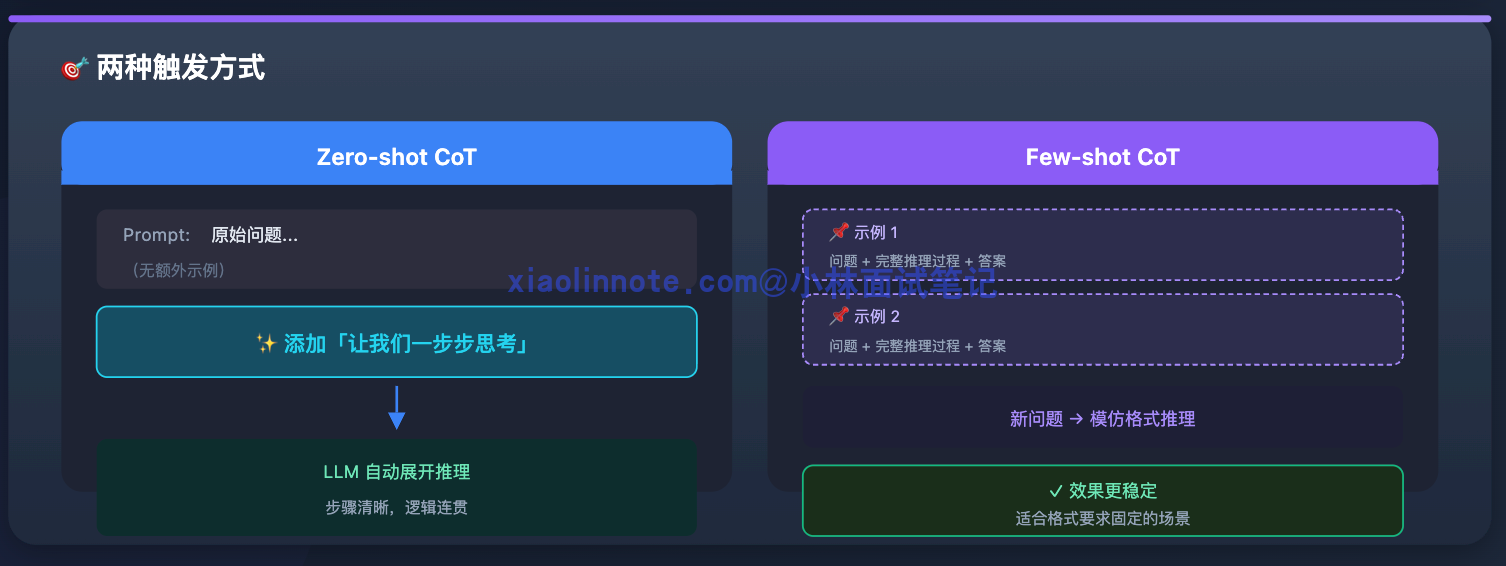
- 一种是 Zero-shot CoT,直接在 prompt 末尾加上「让我们一步步思考」,LLM 自己展开推理,不需要额外示例;
- 另一种是 Few-shot CoT,给几个带有完整推理过程的例子让 LLM 模仿,效果更稳定,适合格式要求比较固定的场景。
但 CoT 有一个根本性的局限:它是纯文字推理,没有办法和外部世界交互。推理过程再完整,也拿不到实时数据,不能执行计算,不能访问数据库。
如果你问 LLM「现在苹果公司的市值是多少?」,它只能根据训练数据里的知识回答,而那些知识可能已经过时好几个月了。这就是 CoT 不够用的地方,你需要的不只是一个能把推理写出来的 LLM,而是一个能在推理过程中「出去拿数据」「执行工具」再「回来继续推理」的系统。于是有了 ReAct。
ReAct 是什么?
ReAct 是 Reasoning and Acting 的缩写,核心思路是在 CoT 的推理链里,插入真实的「行动」。它让 LLM 按照「思考 -> 行动 -> 观察」这个循环来推进任务:先思考当前该怎么做,然后调用一个工具去获取信息或执行操作,把工具返回的结果作为新的「观察」接收回来,再进入下一轮思考,直到 LLM 判断任务完成。
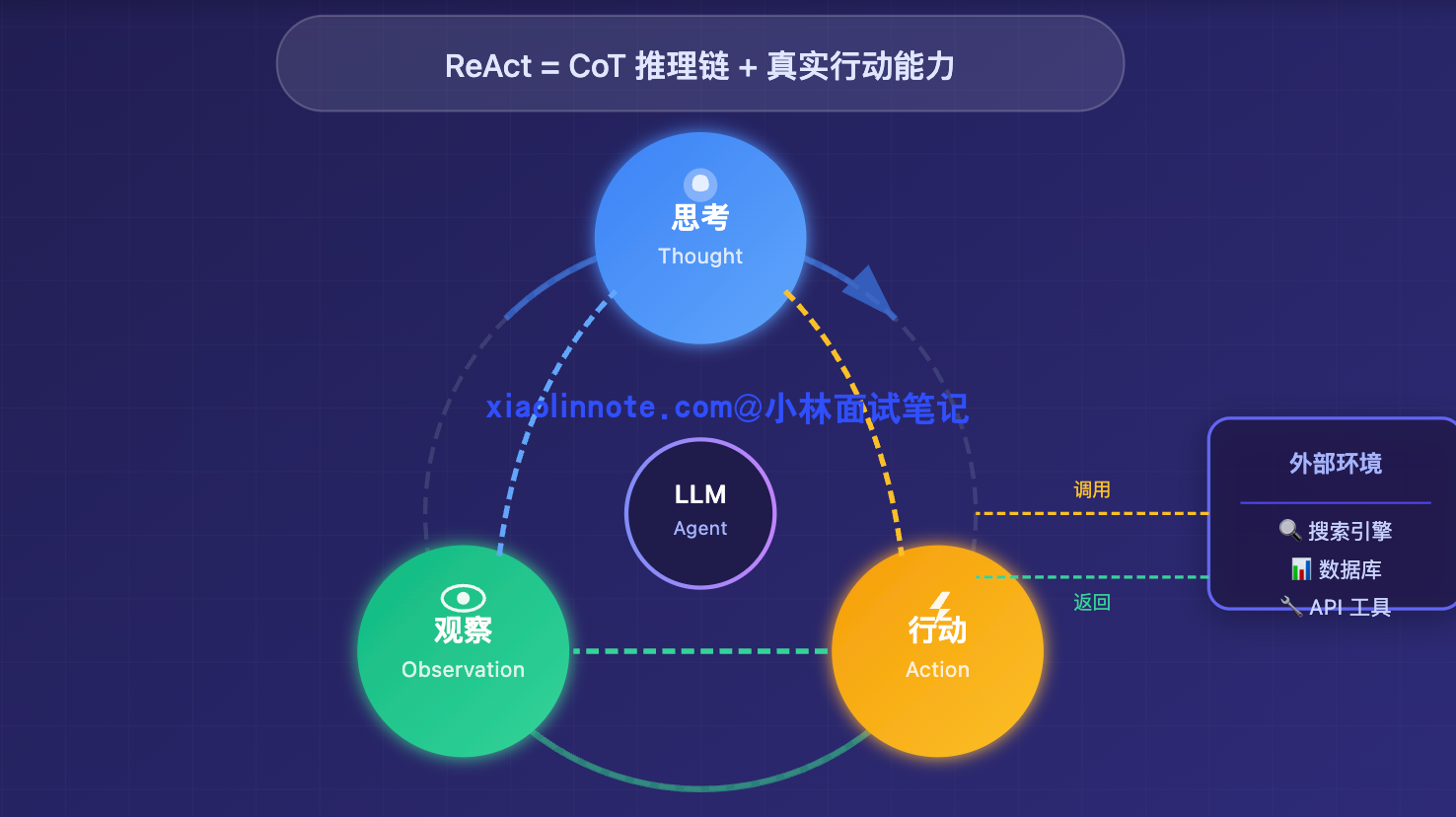
用一个具体例子来感受这个循环。假设你问 Agent「2024 年苹果公司和谷歌的市值谁更高?差多少?」,如果只靠 CoT,LLM 只能说出它训练时知道的数字,可能已经不准了。但用 ReAct,整个过程会是这样的:
Thought: 这道题需要两家公司的实时市值数据,我得先查苹果的市值
Action: search
Action Input: 苹果公司 2024 年市值
Observation: 苹果公司 2024 年市值约为 3.5 万亿美元
Thought: 好,苹果的数字有了,再查谷歌的
Action: search
Action Input: 谷歌 2024 年市值
Observation: 谷歌 2024 年市值约为 2.1 万亿美元
Thought: 两个数字都有了,苹果 3.5 万亿,谷歌 2.1 万亿,苹果更高,差距是 1.4 万亿
Final Answer: 苹果公司 2024 年市值约 3.5 万亿美元,谷歌约 2.1 万亿美元,苹果更高,差距约 1.4 万亿美元每一个 Thought 是 LLM 的推理,每一个 Action 是它决定调什么工具,每一个 Observation 是工具执行后系统填进去的真实结果,最后 Final Answer 是任务完成的终止信号。推理和真实数据的获取是交织在一起的,这才让 Agent 能处理「需要实时信息」或「需要执行操作」的任务。
ReAct 的实现原理,是通过 prompt 格式来约束 LLM 的输出结构,但这个循环不是 LLM 自己在转,而是由你的代码来驱动的。LLM 每次只做一件事:根据当前的历史,输出下一步的 Thought 加上 Action。你的代码负责检测它的输出,判断「有没有 Final Answer」,如果没有就解析出 Action、执行对应的工具、把工具结果作为 Observation 填回历史,再次调用 LLM,一轮一轮地转。一个典型的 ReAct prompt 长这样:
你是一个 AI 助手,可以使用以下工具:
- search(query): 搜索互联网获取最新信息
- calculator(expr): 计算数学表达式
回答时请严格按照以下格式:
Thought: 你的思考过程(分析当前情况,决定下一步)
Action: 工具名称
Action Input: 工具的输入参数
Observation: (此行由系统填入工具返回的结果,你不用写)
... 以上可以重复多轮 ...
Final Answer: 当你确定可以回答时,在这里给出最终答案
问题:2024 年苹果公司的市值是多少?和谷歌相比谁更高?然后你的代码跑一个循环,不断地「调 LLM、检查输出、执行工具、把结果填回去」:
def react_agent(question: str, tools: dict, max_steps: int = 10):
# 把 ReAct 格式约束和问题拼在一起,作为初始 prompt
prompt = build_react_prompt(question, tools)
# 用来存每一轮的对话历史,每次调 LLM 都把完整历史带上
history = []
for _ in range(max_steps):
# 调 LLM,让它输出下一步的 Thought + Action
# 注意:每次调用都把完整历史拼进去,LLM 才知道之前做了什么
response = llm.generate(prompt + "\n".join(history))
if "Final Answer:" in response:
# LLM 输出了 Final Answer,说明它判断任务完成了
return response.split("Final Answer:")[-1].strip()
# 从 LLM 输出里解析出 Action 名称和 Action Input
# 例如:Action: search,Action Input: 苹果公司市值 -> ("search", "苹果公司市值")
action, action_input = parse_action(response)
# 执行对应的工具,拿到真实结果
if action in tools:
observation = tools[action](action_input)
else:
# 如果 LLM 填了一个不存在的工具名,给它一个错误反馈
observation = f"工具 {action} 不存在,请选择可用工具"
# 把这一轮的 LLM 输出(含 Thought+Action)和 Observation 都追加进历史
# 下次调 LLM 时这些内容会成为它的「记忆」
history.append(response)
history.append(f"Observation: {observation}")
return "超过最大步数,任务未完成"整个 loop 里,真正的「智能」全在 LLM 每次输出的 Thought 里,它在分析当前情况、做出下一步决策。你的代码框架做的事是:管理对话历史、执行工具、检测循环终止条件。两件事分工很清楚,理解了这个分工,ReAct 就不再神秘了。
需要补充一点:上面描述的是 ReAct 的经典实现,靠 prompt 格式约束加文本解析来驱动工具调用。
现代 LLM(GPT-4、Claude 3 之后)基本都原生支持 Function Calling / Tool Use,模型可以直接输出结构化的 JSON 工具调用,不再需要靠解析 Action: xxx 这种文本格式。这让 ReAct 的实现更干净,也更可靠,不容易因为 LLM 输出格式不规范而解析失败。本质上「思考 -> 行动 -> 观察」的循环没变,只是「行动」这一步从解析文本变成了解析结构化 JSON。
ReAct 的主要代价是 token 消耗随步骤数线性增长,因为每次调 LLM 都要把完整历史带上,任务步骤越多,输入就越长,成本可观。还有一个值得了解的变体叫 ReWOO(Reasoning WithOut Observation),针对的是「步骤之间没有依赖」的场景:先让 LLM 一次性把所有需要调用的工具和参数全部规划出来,然后并行执行所有工具,最后把结果一次性汇总。
整个任务只需要调用 LLM 两次(规划和汇总),而不是每步都调一次,大幅减少调用次数。但适用场景有限,一旦某个步骤的执行依赖前一步的结果,就没法提前规划了,因为规划时还不知道中间结果是什么。
6. 复杂任务怎么做的任务拆分?为什么要拆分?效果如何提升?
💡 简要回答
我理解任务拆分的原因是 LLM 一次性处理太复杂的任务很容易出错,把大任务拆成小步骤,每步聚焦一件事,准确率会明显提升。拆分方式主要有两种:一种是静态拆分,提前把步骤写死;另一种是动态拆分,让 LLM 自己根据目标规划步骤,更灵活但也更难控制。拆完之后步骤之间可能有依赖关系,我的经验是把能并行的步骤并发跑,端到端延迟可以降很多,有时能降 40% 到 60%。
📝 详细解析
为什么任务要拆分?
先从一个具体的失败案例说起,感受一下为什么任务拆分是必要的。
你让一个 LLM 一次性完成「帮我写一份竞品分析报告」,它需要搜索多家竞品的信息、整理核心功能对比、分析各自优缺点、写结论。听起来是一件事,但其实是四件完全不同的事混在一起。LLM 收到这个任务,往往会出现这几种毛病:在搜索阶段就开始掺杂分析意见,在写对比表格时突然引入新的竞品信息,报告写到一半忘掉了前面整理的某个关键数据点,最后输出一篇结构混乱的文章,读下来感觉什么都有、什么都不深。
这不是偶发的问题,而是有系统性原因的。LLM 的工作台,也就是 context window,是有大小限制的,能同时处理的信息量是有上限的。任务越大,中间状态越多,桌面就越乱:搜索结果、分析意见、写了一半的段落全部堆在一起,LLM 很难持续追踪「我现在在做哪个子目标」。就像让一个人同时记住十件事并全部做对,比让他每次只专注做一件事出错率高得多。
任务拆分要解决的,就是这个「桌面太乱」的问题。把一个大目标切成多个小步骤,每个步骤只做一件事,LLM 的全部注意力都集中在这一件事上,桌面保持干净,质量自然高。而且还有一个额外的好处:每一个步骤都是独立的输出,可以被单独检查和验证。某一步出了问题,重试那一步就行,不需要从头跑整个任务。
任务拆分两种思路
任务拆分有两种思路,一种是你自己来拆,一种是让 LLM 来拆。
静态拆分是你提前把任务流程设计好,固定成一个确定的 Workflow,每一步是什么、按什么顺序执行,全部事先写死。比如「写一篇技术博客」,固定拆成:搜索资料 -> 整理大纲 -> 逐段撰写 -> 润色校对,四步顺序执行。好处是行为完全可预测,出了问题知道是哪一步的问题,好排查;坏处是灵活性低,遇到你没设计进流程的情况就容易卡住。
动态拆分则是把「任务拆解」这件事本身也交给 LLM 来做。你给它一个目标,让它先输出一个执行计划,再按计划一步步执行,这是 Plan-and-Execute 模式的核心思想。
用项目管理来类比。一个没有经验的程序员接到任务「开发用户登录系统」,可能会直接开始写代码,边写边想「接下来要做什么」,结果很容易漏掉某个环节,比如忘了写错误处理,或者到最后才想起来要做密码加密。但一个有经验的工程师会先写项目计划:需求分析 -> 数据库设计 -> 接口设计 -> 编码实现 -> 安全测试,把整体结构想清楚了再开始动手。Plan-and-Execute 就是给 LLM 引入这个「先规划再执行」的习惯,把「想清楚要做什么」和「真正去做」分成两个独立的阶段。
整个 Plan-and-Execute 流程分三个阶段:

- 第一阶段是规划,把目标告诉 LLM,让它输出有序的步骤列表,只做规划,不做任何实际执行;
- 第二阶段是执行,拿着计划逐步执行每个步骤,每一步都要把前面所有步骤的结果作为 context 传进去,LLM 始终知道整件事做到哪里了,不会「失忆」;
- 第三阶段是汇总,所有步骤跑完之后,把各步骤的产出整合在一起生成最终输出。动态拆分的优势是灵活性强,LLM 可以根据具体任务的特点制定最合适的计划;劣势是规划质量不稳定,规划一旦出了问题,后续所有执行步骤都建立在错误的基础上。
步骤拆好之后,还有一件重要的事:分析步骤之间的依赖关系。有些步骤必须等前一步完成才能开始,有些步骤之间没有依赖,可以同时进行。识别出可以并行的步骤,是降低总耗时的关键。
用厨师做饭来建立直觉。你要同时处理三件事:烧水、切菜、腌肉。如果傻傻地串行,等水烧开了再切菜,切完菜再腌肉,总时间是三件事之和。但一个有经验的厨师会这样:先烧水,烧水的同时切菜腌肉,水开了三件事都好了,直接下锅。总时间由「最长的那条路径」决定,也就是烧水的时间,因为切菜和腌肉都在等水开的过程中完成了。并行执行降低的不是「每步的时间」,而是「关键路径的总时间」。
回到 Agent 的场景,假设你有步骤 1、2、3、4,其中步骤 3 依赖步骤 1 的结果,步骤 4 依赖步骤 2 和步骤 3:
import asyncio
async def execute_parallel_steps(independent_steps: list):
# asyncio.gather 让多个步骤同时开始执行,不等某一个完成再启动下一个
# 这就像厨师烧水的同时切菜,两件事并发进行
tasks = [execute_step_async(step) for step in independent_steps]
results = await asyncio.gather(*tasks) # 等所有并发步骤都完成,一起拿结果
return results
# 依赖图:步骤 1 和步骤 2 相互独立,可以并行
# 步骤 3 需要步骤 1 的结果才能开始
# 步骤 4 需要步骤 2 和步骤 3 都完成才能开始
#
# 步骤1 ──────────────┐
# ├──> 步骤3 ──┐
# 步骤2 ──────────────┘ ├──> 步骤4(最终输出)
# └────────────────────── ┘如果这四步全部串行,总时间是四步之和。识别出依赖关系并行执行后,关键路径变成「步骤1/2(并行)-> 步骤3 -> 步骤4」,假设每步各需要 3 秒,串行是 12 秒,并行之后是 9 秒。步骤越多、可并行的越多,节省的时间越可观,实际项目里降低 40% 到 60% 的端到端延迟是很正常的数字。
任务不是拆得越细越好,粒度的把握很重要。拆太细有两个代价:步骤越多、LLM 调用次数越多,总 token 消耗上升;而且步骤太碎,每步只做一件极小的事,LLM 看不到全局,产出的各部分容易衔接生硬。拆太粗又回到了原来的问题:每步负责的事太多,出错概率上升,也无法定位问题出在哪一步。
实践中通常把「原子操作」作为划分单步的标准:这个步骤只做一件独立的事,边界清晰,做完有明确的输出,和其他步骤不互相依赖。
具体举例感受一下区别。「搜索竞品 A 的产品信息」是原子的,只做一件事(搜索),有明确的输入和输出,做完就完了。「整理竞品分析」不是原子的,它包含了搜索信息、筛选关键点、格式化输出三件事,还没开始就已经有三个子任务了。判断一个步骤是不是原子的,有一个简单方法:你能给它写一个清晰的函数签名吗?能的话,它大概是原子的;如果你发现函数里还要分好几个阶段、处理好几类情况,那大概需要再拆。
7. 请你介绍一下 AI Agent 的记忆机制,并说明在实际开发中应该如何设计记忆模块?
💡 简要回答
Agent 需要记忆才能在多步任务中保持状态、跨任务积累知识。记忆机制分四层:感知记忆(当前输入的原始内容)、短期记忆(context window 里的对话历史)、长期记忆(存在外部数据库、语义检索召回)、实体记忆(结构化提取的关键事实)。实际设计时要解决三个核心问题:存什么、怎么存、什么时候取出来用,根据信息类型选合适的存储方式,再搭配主动检索和按需检索两种策略使用。
📝 详细解析
没有记忆的 Agent 有多不好用
要搞清楚记忆机制为什么重要,得先感受一下「没有记忆」的 Agent 到底有多难用。
你今天告诉 Agent「我喜欢代码风格简洁、变量命名用英文、不要过度注释」,它帮你完成了今天的任务。明天你重新打开对话,让它帮你写一个新功能,它输出的代码风格完全和昨天说好的不一样,中文注释一堆,变量名也很啰嗦。你很困惑,但对 Agent 来说,昨天的对话压根不存在,每次对话都是全新的开始,之前达成的所有约定都消失了。
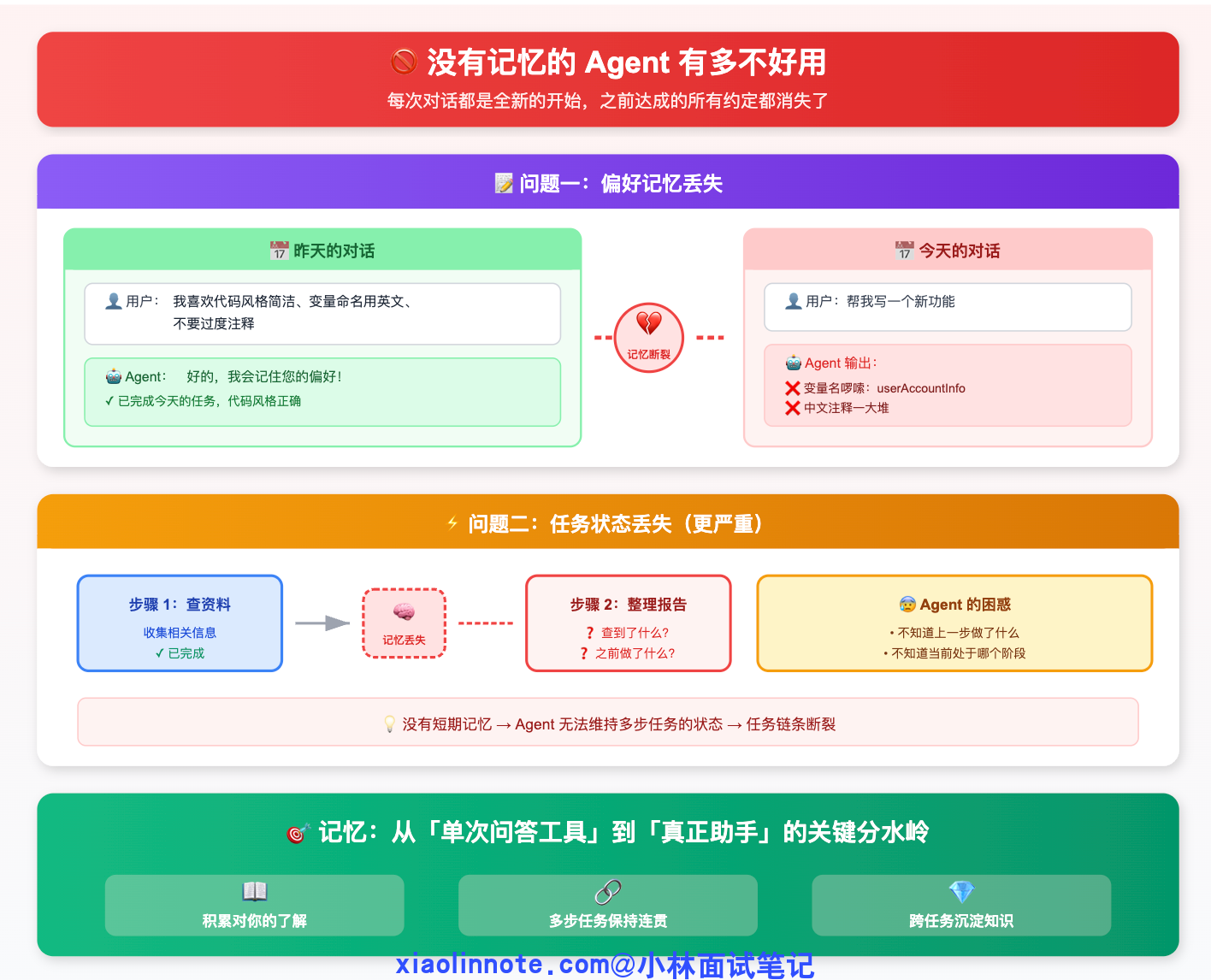
这还只是「偏好记忆」的问题。更严重的是「任务状态」的问题:Agent 在执行一个多步任务的过程中,如果没有短期记忆来维持状态,它就不知道自己上一步做了什么、当前处于哪个阶段、已经收集到了哪些信息。你让它「先查资料,再整理成报告」,没有记忆的话,整理报告这一步根本不知道查到了什么。
记忆,是 Agent 从「单次问答工具」变成「真正助手」的关键分水岭。有了记忆,它才能积累对你的了解,才能在多步任务中保持连贯,才能跨任务沉淀知识。
四种记忆类型(从最短暂到最持久)
记忆机制其实可以对应到人类的记忆系统来理解,从最短暂到最持久,分四个层次。
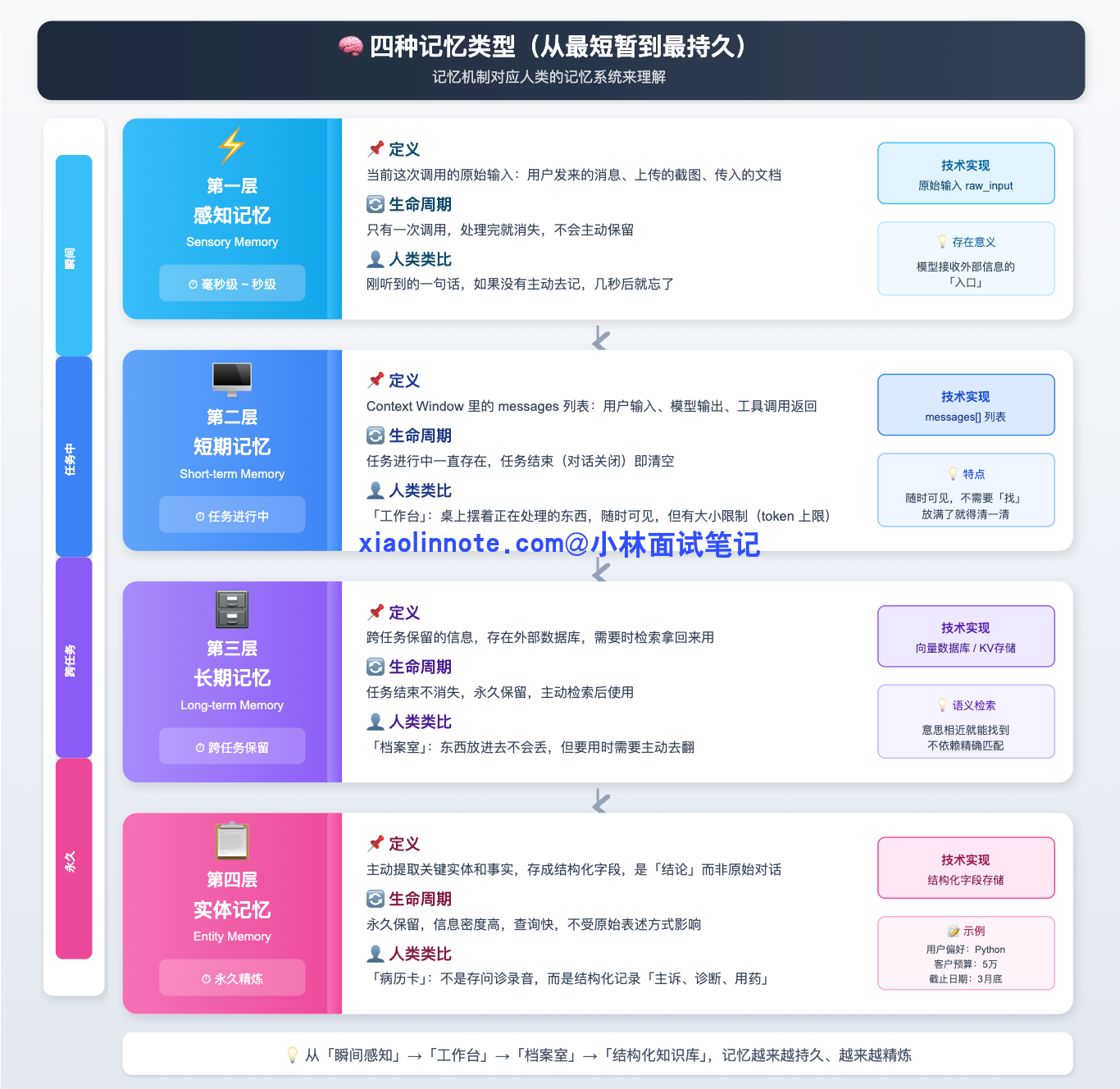
第一层:感知记忆(Sensory Memory)
这是最短暂的一层,就是「当前这次调用的原始输入」,用户发来的这条消息、上传的截图、传入的文档。它的生命周期只有一次调用,处理完就消失,不会主动保留。
类比到人:你刚听到的一句话,如果没有主动去记,几秒后就忘了。感知记忆就是这个「刚进来还没处理」的原始感知。它存在的意义是:模型需要一个「入口」来接收外部信息,这就是感知记忆的角色。
第二层:短期记忆(Short-term Memory)
这是 context window 里的 messages 列表,维持着当前任务执行过程中的完整状态,包括用户说了什么、模型输出了什么、工具调用返回了什么。只要任务还在进行,这些信息就都在;任务结束(对话关闭),这块记忆就清空了。
类比到人:这就像你的「工作台」,桌上摆着的都是正在处理的东西。工作台有大小(token 上限),放满了就得清一清。工作台的特点是「随时可见」,不需要去「找」,直接读就行。
第三层:长期记忆(Long-term Memory)
这是跨任务保留的信息,存在外部数据库里,通常是向量数据库、关系数据库或 Key-Value 存储。任务结束了,信息不会消失,下次需要时去检索拿回来用。
类比到人:这就是你的「档案室」,东西放进去不会丢,但要用的时候需要主动去翻。长期记忆的关键技术是向量数据库,它支持「语义检索」:你不需要知道存的时候用了什么关键词,只要意思相近就能检索到相关内容。这比精确匹配灵活得多,比如你存的是「用户不喜欢冗长的注释」,用「代码风格偏好」去查也能找到它。
第四层:实体记忆(Entity Memory)
这层比长期记忆更精炼,它不是存原文,而是把对话中出现的关键实体和事实主动提取出来,存成结构化字段。比如「用户偏好 Python」「客户预算是 5 万」「项目截止日是 3 月底」,这些是从对话里提炼出来的「结论」,而不是原始对话本身。
类比到人:这就像医生的病历卡,不是把问诊录音存起来,而是结构化地记录「主诉:头痛三天;诊断:偏头痛;用药:布洛芬」。信息密度高,查询快,而且不受原始表述方式影响。
四层记忆横向对比:
| 类型 | 载体 | 容量 | 生命周期 | 访问方式 |
|---|---|---|---|---|
| 感知记忆 | 当次输入 | 极小 | 单次调用 | 即时访问 |
| 短期记忆 | context window | 受 token 限制 | 一次任务 | 直接读取 |
| 长期记忆 | 向量/关系数据库 | 无限 | 持久 | 语义检索 |
| 实体记忆 | 结构化存储 | 无限 | 持久 | 精确查询 |
实际设计记忆模块的三个核心问题
理解了四种记忆类型,设计记忆模块时还要解决三个工程问题。
第一个:存什么?
不是所有内容都值得写入长期记忆,存太多反而会引入噪音,让检索的精准度下降。判断标准其实很简单:「这条信息,下次任务开始时如果知道,会让 Agent 做得更好吗?」
通常值得存的有三类:用户偏好和习惯(语言风格、技术栈偏好、工作习惯)、任务执行中产生的关键结论和决策(比如「调研发现竞品 A 的定价策略是按用量收费」)、以及外部知识(产品文档、FAQ、历史案例)。
不值得存的:中间推理过程、工具返回的原始数据(日志太啰嗦)、闲聊内容。这些存进去只会稀释有价值的记忆,让检索的信噪比下降。
第二个:怎么存?
根据信息的类型选合适的存储介质,而不是一刀切地全部塞进向量数据库:
- 需要语义检索的内容(文档知识、对话摘要)-> 向量数据库,用 embedding 存储,检索靠相似度
- 结构化的用户偏好、状态字段(语言偏好、项目配置)-> 关系数据库或 Key-Value,支持精确查询,速度快
- 整段文档或知识库 -> 向量数据库,配合 RAG 召回
混合存储是主流做法:结构化的偏好字段用关系数据库精确查,非结构化的知识和历史用向量数据库语义检索,两者配合使用。
第三个:什么时候取出来用?
两种策略,实践中结合使用:
「主动检索」:任务开始前,用当前任务的描述去检索相关记忆,把结果注入 system prompt 作为背景知识。这样 Agent 一开始就带着「历史记忆」进入任务,不需要用户每次重新交代背景。
「被动触发」:Agent 在推理过程中,判断当前步骤需要某类特定知识时,主动发起检索(把「查记忆」封装成一个 Tool,让 Agent 自己决定什么时候调)。这种方式更灵活,但依赖模型判断什么时候该去查。
实践上两种结合:session 开始时做一次主动检索,把关于用户偏好和背景的记忆加载进 system prompt;任务执行过程中,遇到需要专业知识或历史数据的步骤,再让 Agent 按需检索。
完整记忆模块的配合方式
把四层记忆和三个核心问题放在一起,来走一遍一次完整任务里它们是怎么协作的。整个过程可以用「读 -> 用 -> 写」三个阶段来描述。
第一阶段:任务开始前,先「读」记忆
用户发来一个新请求,Agent 不是立刻开始干活,而是先去「翻档案」:从实体记忆里取出用户的结构化偏好(语言偏好、风格要求、过往决策),再用任务描述作为查询词,去长期记忆里做一次语义检索,拿回最相关的历史背景。把这两部分信息拼进 system prompt 的开头,Agent 进入任务时就已经带着完整的「用户画像」,不需要用户重复交代背景。
第二阶段:任务执行中,持续「用」记忆
任务开始执行,短期记忆(messages 列表)全程工作:用户的每一条消息、模型的每一次输出、工具调用返回的每一个结果,都追加进 messages。每次调用 LLM 都把这份完整历史带上,Agent 始终知道自己做到哪一步、前面发现了什么。
如果某个执行步骤需要特定的专业知识(比如查某个 API 的文档、回想某次历史决策),Agent 可以临时发起一次长期记忆检索,把「查记忆」封装成一个 Tool,用当前上下文作为查询词,把检索结果注入到这一步的 context 里,用完即走,不需要永久保留在 messages 中。
第三阶段:任务结束后,主动「写」记忆
任务完成,进行最后一步:把本次任务产生的新知识写回持久化存储。具体来说,如果用户在对话中表达了新的偏好(「以后写函数都要加类型注解」),就更新实体记忆的对应字段;如果任务产生了有价值的结论(「竞品 A 的定价是按用量收费」),就把这条摘要写入长期记忆,embedding 后存入向量数据库,供下次检索。最后,短期记忆(messages 列表)清空,工作台恢复干净,等待下一个任务。
用流程图来看,整条链路是这样的:
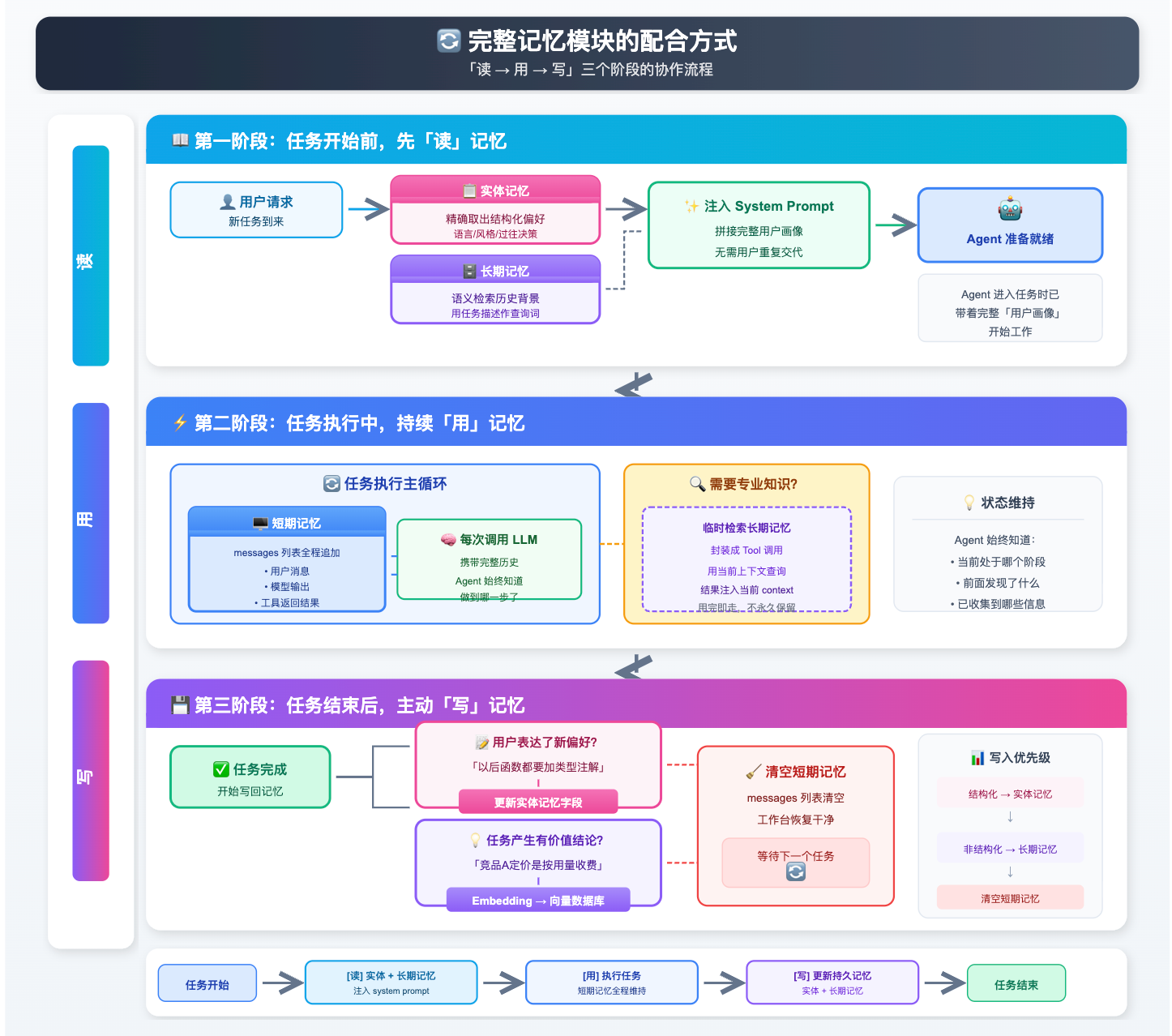
「读 -> 用 -> 写」三个阶段形成完整闭环:每次任务开始时把历史积累读进来,执行中靠短期记忆保持连贯,结束后把新知识写回去沉淀。Agent 用得越多,积累越厚,越来越「了解」用户,这才是记忆系统真正的价值所在。
8. Agent 的长短期记忆系统怎么做的?记忆是怎么存的?粒度是多少?怎么用的?
💡 简要回答
我理解记忆系统分两层。短期记忆就是 context window 里的对话历史,存当前任务的中间状态,任务结束就清掉;长期记忆用向量数据库存,把信息 embedding 后写入,用的时候做语义检索拿回来注入 prompt。粒度上我通常按「一次完整交互」或「一个关键事件」为单位存,太细碎检索噪音大,太粗糙又丢失细节,这个需要根据业务实际调整。
📝 详细解析
先假设一个没有记忆系统的 Agent,感受一下它会有多不堪用。
你今天找它说「帮我优化这段 Python 代码,风格要简洁一点,变量命名用英文」,它帮你优化好了。明天你又找它说「帮我写一个爬虫脚本」,它输出了一段用中文变量命名的代码,风格也很啰嗦。你很困惑,昨天不是刚说好了吗?对它来说,昨天的对话压根不存在。它不记得你的偏好,不记得你们达成过什么约定,每次对话都是全新的开始,就像每次见面都是第一次认识。
这个「失忆」问题,对单次问答来说不是大问题,但对一个要持续帮你工作的 Agent 来说,意味着它永远无法积累对你的了解,也无法在多次任务之间建立连贯性。记忆系统就是为了解决这件事而存在的:让 Agent 既能在一次任务执行过程中保持状态,也能跨任务记住重要信息。实现上,记忆被拆分成两层,它们解决的问题不同,实现方式也完全不同。
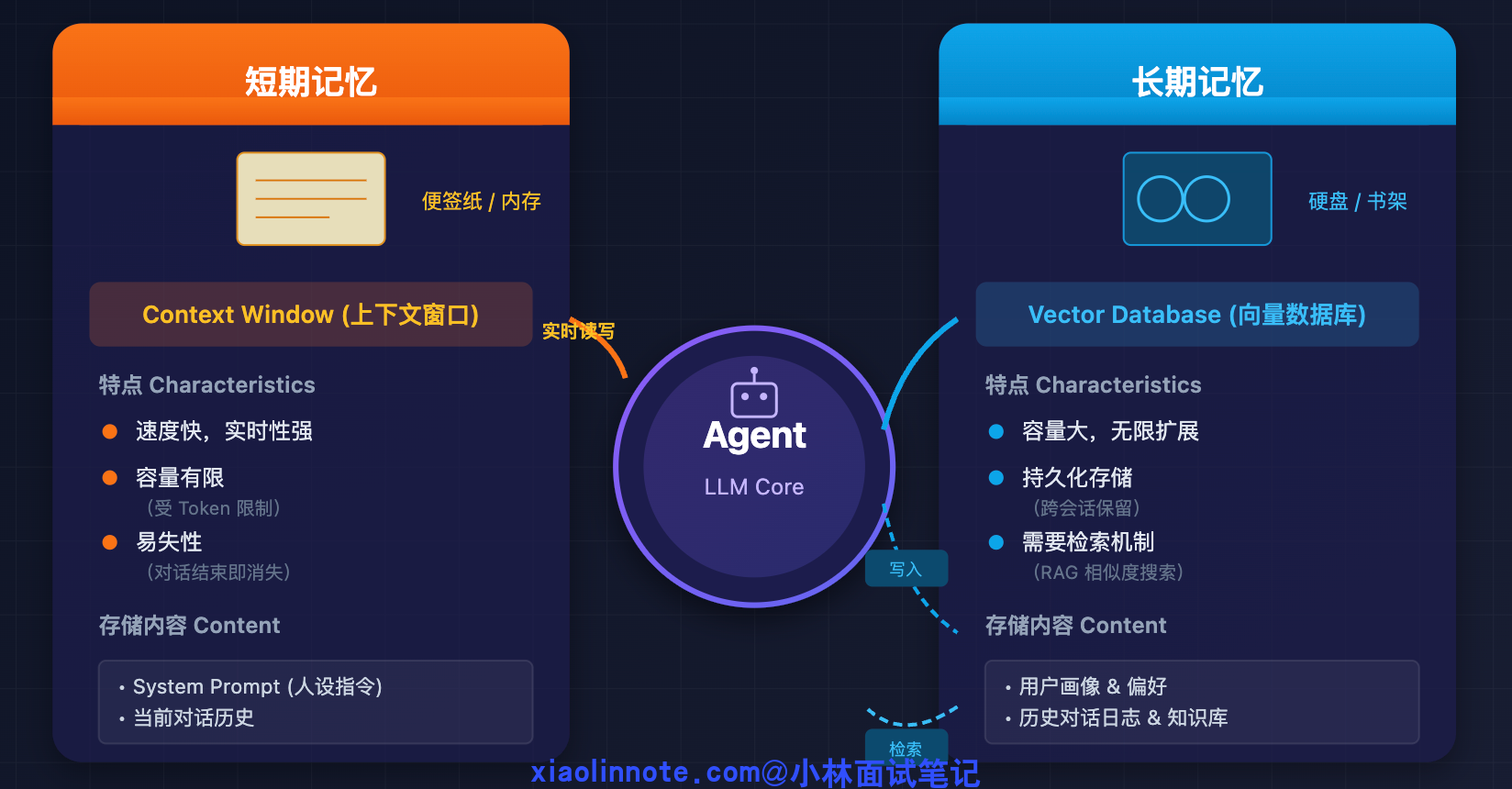
短期记忆
先说短期记忆,它就是你每次调 LLM 时传进去的 messages 列表。你可以把它想象成 LLM 当前的「工作台」,桌面上摆着当前任务的所有相关内容:用户的指令、LLM 自己的思考过程、工具调用的结果、每一步的中间状态。LLM 靠这张桌面知道「我在做什么、做到哪了、前面几步发现了什么」。
实现上非常直接,就是维护一个列表,每一步产生的内容都追加进去:
class ShortTermMemory:
def __init__(self):
# messages 列表就是 LLM 的工作台
# 每条消息有 role(谁说的)和 content(说了什么)
self.messages = []
def add(self, role: str, content: str):
# role 有三种:user(用户输入)、assistant(LLM 输出)、tool(工具返回结果)
# 每一步的内容都要追加进来,保持完整的任务状态
self.messages.append({"role": role, "content": content})
def get_context(self):
# 调 LLM 时把完整的 messages 传进去
# LLM 会读取这份完整历史来理解当前状态
return self.messages
def clear(self):
# 任务结束后清空,准备迎接下一个任务
# 清空意味着这次任务的所有中间状态都消失了
self.messages = []
# 一次任务执行的示例
memory = ShortTermMemory()
memory.add("user", "帮我分析这几家竞品的核心功能差异")
memory.add("assistant", "好的,我先搜索一下竞品 A 的信息")
memory.add("tool", "搜索结果:竞品 A 的核心功能是实时协作编辑,支持最多 50 人同时在线……")
memory.add("assistant", "已拿到竞品 A 的信息,再搜竞品 B")
# 每次调 LLM 都传完整历史,它才能知道自己做到哪一步了
response = llm.chat(messages=memory.get_context())这里有一个重要的点:每次调 LLM 时传的是完整的历史,而不只是最新一条消息。这就是短期记忆的本质,把整个任务状态带在身上。代价是 messages 会随着任务进展越来越长,context window 总有一天会装满,早期的内容就开始被截断,Agent 就开始「遗忘」。
短期记忆在当前任务结束后就清空了,下次来了新任务,桌面是空的,什么都不记得了。要让 Agent 跨任务记住东西,就需要长期记忆。
长期记忆
长期记忆的核心工具是向量数据库(Vector Database)加上 Embedding(向量化),对初学者来说这两个词可能很陌生,先解释清楚。
Embedding 是把一段文字转化成一组数字的过程。这组数字通常有几百到几千个维度,它们共同捕捉了这段文字的「语义」。语义相近的文字,转化出来的数字向量在空间里也靠得很近。
举个类比:你把颜色编码成 RGB,红色是 (255, 0, 0),橙色是 (255, 165, 0),它们的数字距离很近,因为颜色本身就相近。深蓝色是 (0, 0, 139),和红色的数字距离很远,颜色也相差很远。
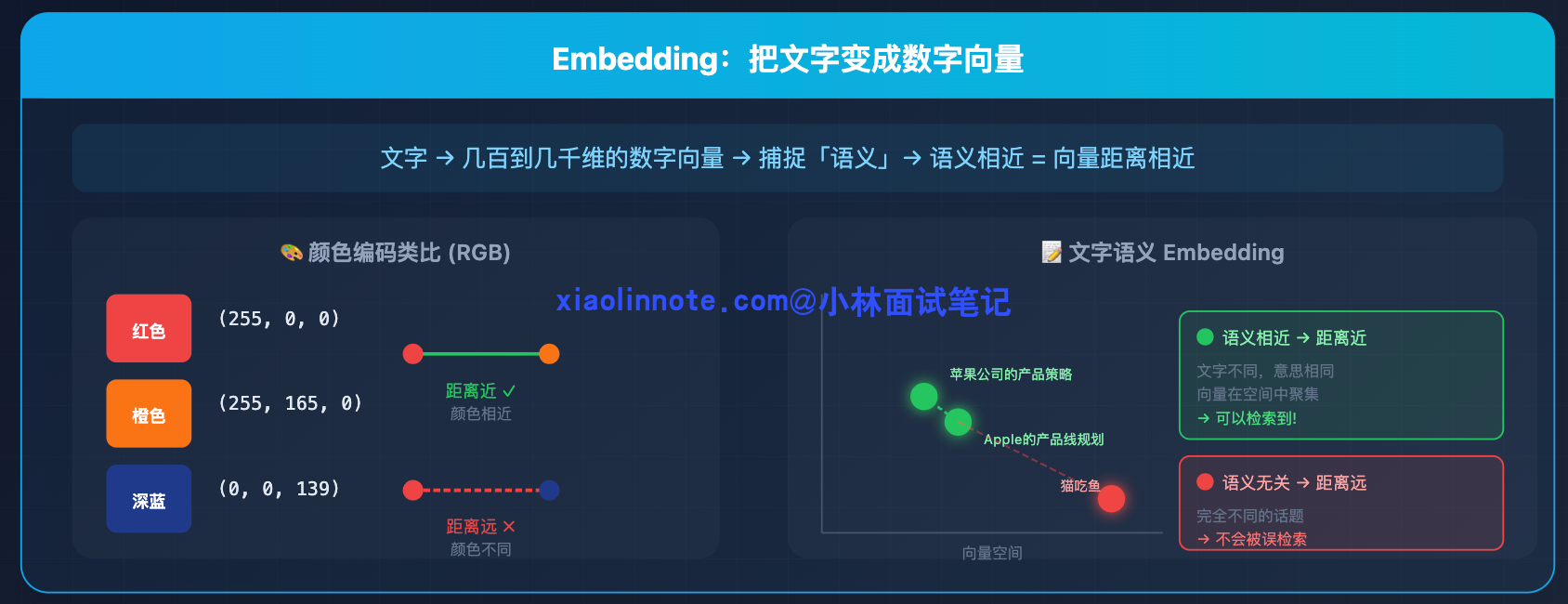
Embedding 对文字做的事是一样的:「苹果公司的产品策略」和「Apple 的产品线规划」,文字不同但语义相近,embedding 出来的向量在空间里距离就很近;「苹果公司」和「猫吃鱼」,语义毫不相关,向量距离就很远。
向量数据库,就是专门存这些数字向量的数据库。它最核心的能力是「相似度检索」:给你一个查询向量,找出数据库里和它距离最近的几条记录,也就是语义最相关的内容。
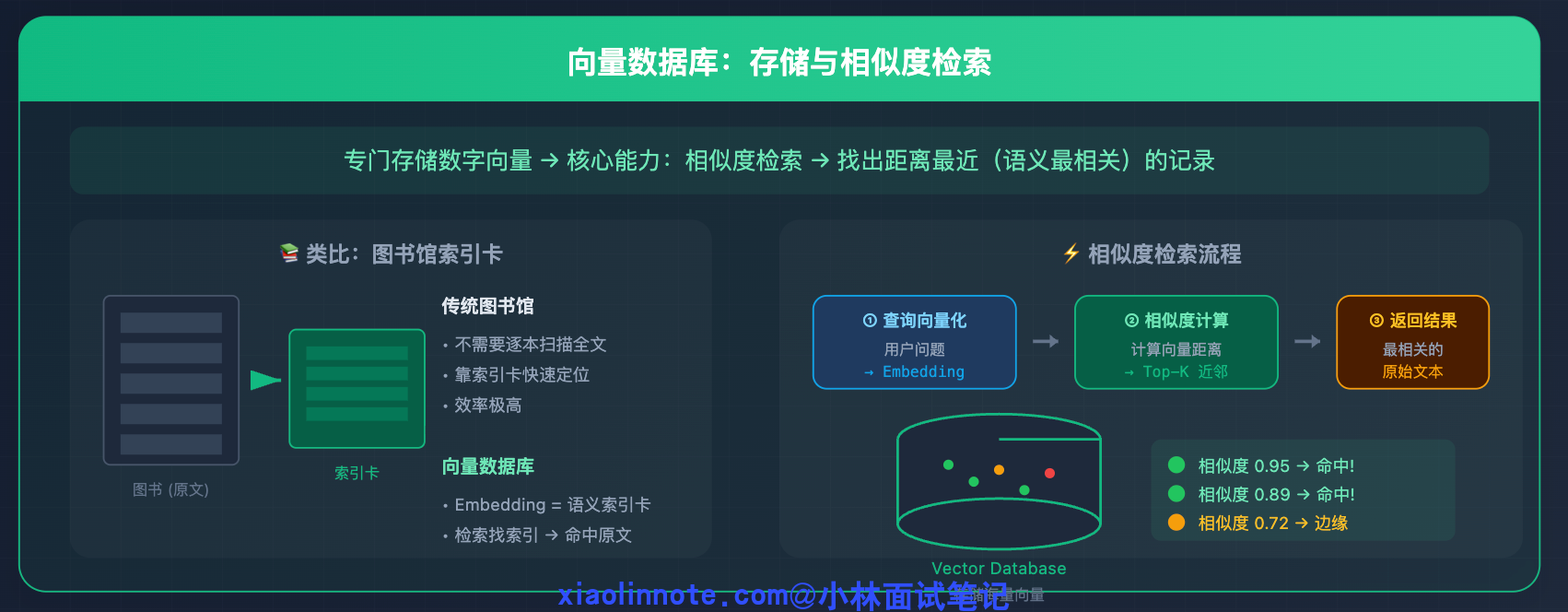
你可以用图书馆的索引卡来类比:找书时你不需要逐本扫描全文,而是靠索引卡快速定位相关书目,向量数据库里的 embedding 就是这些「语义索引卡」,检索时找索引、命中原文,效率极高。
把两者结合:存的时候,把信息转成向量和原文一起存进去;取的时候,把当前的问题也转成向量,找数据库里语义最相关的记忆拿出来。
from openai import OpenAI
import chromadb
client = OpenAI()
# ChromaDB 是一个轻量的向量数据库,适合本地开发使用
db = chromadb.Client()
# 创建一个「集合」,类似于关系数据库里的表,用来存 Agent 的长期记忆
collection = db.get_or_create_collection("agent_memory")
def save_to_long_term(content: str, metadata: dict):
# 第一步:把文字内容转成 embedding 向量
# text-embedding-3-small 是 OpenAI 的 embedding 模型,把文字变成数字向量
embedding = client.embeddings.create(
input=content,
model="text-embedding-3-small"
).data[0].embedding # 得到一个几百维的浮点数列表
# 第二步:把向量、原文、元信息一起存进向量数据库
collection.add(
embeddings=[embedding], # 这是「索引」,用于相似度检索
documents=[content], # 这是原文,检索命中后返回给 LLM 直接使用
metadatas=[metadata], # 附加信息,比如存入时间、任务类型、重要程度
ids=[f"mem_{hash(content)}"]
)
def retrieve_memory(query: str, top_k: int = 3) -> list[str]:
# 第一步:把当前查询也转成 embedding 向量
# 和存储时用的是同一个 embedding 模型,这样「语义距离」才有可比性
query_embedding = client.embeddings.create(
input=query,
model="text-embedding-3-small"
).data[0].embedding
# 第二步:在向量数据库里找「向量距离最近」的几条记录
# 向量距离近 = 语义相近 = 内容最相关
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k # 只取前 top_k 条,避免检索出太多噪音
)
# 返回的是原文文本列表,LLM 可以直接读取这些记忆内容
return results["documents"][0]存的时候,把内容转成向量和原文一起存;取的时候,把当前问题也转成向量,找向量空间里最近的几条记忆。「语义相似 = 向量距离近」这个特性,让你不需要精确匹配关键词,靠意思相近就能把相关记忆检索出来。
存长期记忆时,「一次存多少内容」这个粒度问题非常关键,直接影响后续检索的质量。
粒度太细,每句话存一条,会产生什么问题?假设你把「用户偏好 Python,不喜欢全局变量,风格追求简洁,注释要用英文」拆成四条记忆,下次检索时可能只命中了其中某几条,其他的被遗漏了,记忆碎片化,LLM 拿到的是不完整的偏好信息。
粒度太粗,把一整次任务的完整记录存成一条,又会有什么问题?假设一次完整对话有两千个 token 存成一条,检索时命中了,但这两千个 token 里真正和当前问题相关的可能只有一百个,LLM 要在一堆无关内容里找到真正有用的信息,很容易被干扰。
比较合理的粒度是按「一次完整交互」或「一个独立的知识点/事件」来存。前者是用户的一个具体请求加上 Agent 处理结果,信息完整性好;后者是把「用户偏好:Python,简洁风格,英文注释」打包成一条结构化记录,检索时一次拿到完整偏好,不会碎片化。过程中的每一步细小中间结果通常不需要存长期记忆,短期记忆够用。
把两层记忆放在一个具体场景里来感受它们是怎么配合的。用户第一次来,说「帮我优化这段 Python 代码」。执行过程中,短期记忆维持整个对话状态,存着用户发的代码、LLM 的分析过程、优化后的结果。任务结束后,把「该用户偏好 Python,代码风格简洁,变量命名用英文」这条信息存进长期记忆。
两天后用户回来说「帮我写一个网页爬虫」。Agent 在开始任务之前,先用「网页爬虫」检索长期记忆,拿回来的相关记忆里包含了那条偏好信息。Agent 把这条信息注入 system prompt,然后开始任务,写出来的爬虫脚本自然就符合用户偏好了,用户会感觉「这个 AI 真了解我」,实际上是长期记忆在背后起了作用。
def run_agent_with_memory(user_request: str, long_term_memory, short_term_memory):
# 第一步:任务开始前,用任务描述检索长期记忆,拿出相关历史
# 这一步让 Agent「想起」和当前任务相关的历史经验和用户偏好
relevant_memories = long_term_memory.retrieve(user_request, top_k=3)
# 第二步:把检索到的长期记忆注入 system prompt
# LLM 会把这些信息当作背景知识,影响它这次任务的处理方式
system_prompt = f"""你是一个智能助手。
以下是用户的相关历史信息,请在处理任务时参考:
{chr(10).join(relevant_memories)}"""
short_term_memory.add("system", system_prompt)
short_term_memory.add("user", user_request)
# 第三步:整个任务执行过程中,靠短期记忆维持状态
# 每一步的中间结果都追加进 messages,LLM 始终知道做到哪里了
result = execute_task_with_short_term_memory(short_term_memory)
# 第四步:任务完成后,把重要结论写入长期记忆
# 这次任务产生的新知识就沉淀下来,下次可以用
if result.is_important:
long_term_memory.save(
content=result.summary,
metadata={"task_type": "coding", "timestamp": now()}
)
return result短期记忆在任务执行的整个过程中起作用,是那个时刻在变化的「工作台」;长期记忆在任务开始前和任务结束后起作用,是沉淀下来的「档案」。前者保证当前任务的连贯性,后者保证跨任务的积累。两层配合,才让 Agent 既不会在一次复杂任务中途失忆,也能随着使用时间的增长,变得越来越「了解」用户。
9. 什么是多智能体系统(Multi-Agent)?
💡 简要回答
多智能体系统就是多个 Agent 协作完成任务,每个 Agent 各有分工,有的负责搜索、有的负责写代码、有的负责做评审。我理解单个 Agent 主要受两个限制:一是 context 窗口大小,复杂任务信息量一多就撑爆了;二是单点能力,什么都让一个 Agent 做,每件事都是泛才。Multi-Agent 通过专业分工和并行执行,能处理更复杂、更长流程的任务,这是我在实际项目里选择多智能体方案的核心原因。
📝 详细解析
想象这样一个场景:你让 Agent 帮你完成「写一份完整的 AI 行业竞品分析报告」。它需要搜索十几家竞品、读懂每家的产品功能、梳理核心差异、整理对比数据、最后写结论……光是搜索下来,每家竞品几百字,十家就是几千字的搜索结果,再加上来回确认的对话历史和中间推理,还没开始写结论,整个工作台就已经快撑满了。
这里说的「工作台」,就是 LLM 的 context window。LLM 处理任务的方式,是把它当前能看到的所有内容,包括你的指令、它自己的推理过程、工具返回的搜索结果、历史对话记录,全部摆在这张工作台上,一起处理。这个工作台是有大小上限的,常见的模型限制是 10 万到 20 万个 token,塞满了之后,早期的内容就会开始「掉落」,就像一张桌子放满了东西,新的东西要放进来,旧的就得推到地上。于是,你三十分钟前确认的方案、搜集的第一批资料,就这么悄悄消失了,Agent 开始「遗忘」。
context 有上限,这是第一个硬限制。但更深的问题其实是「专业度」的问题。让一个 Agent 既搜信息、又写代码、又做测试、又写文档,它在每一件事上都得兼顾,精力是分散的,就像一个人同时担任产品经理、程序员、测试工程师和文档工程师,每个角色都做得不够专注,互相干扰。而且一旦某个环节出问题,整条链路就卡住了,没有隔离性,排查起来也很痛苦。
Multi-Agent 核心思路
Multi-Agent 的核心思路,就是「团队作战代替单打独斗」。

与其让一个 Agent 包揽所有事,不如把任务按职能拆开,每个 Agent 只负责一件事,专心做好自己那块,做完把结果传给下一个。
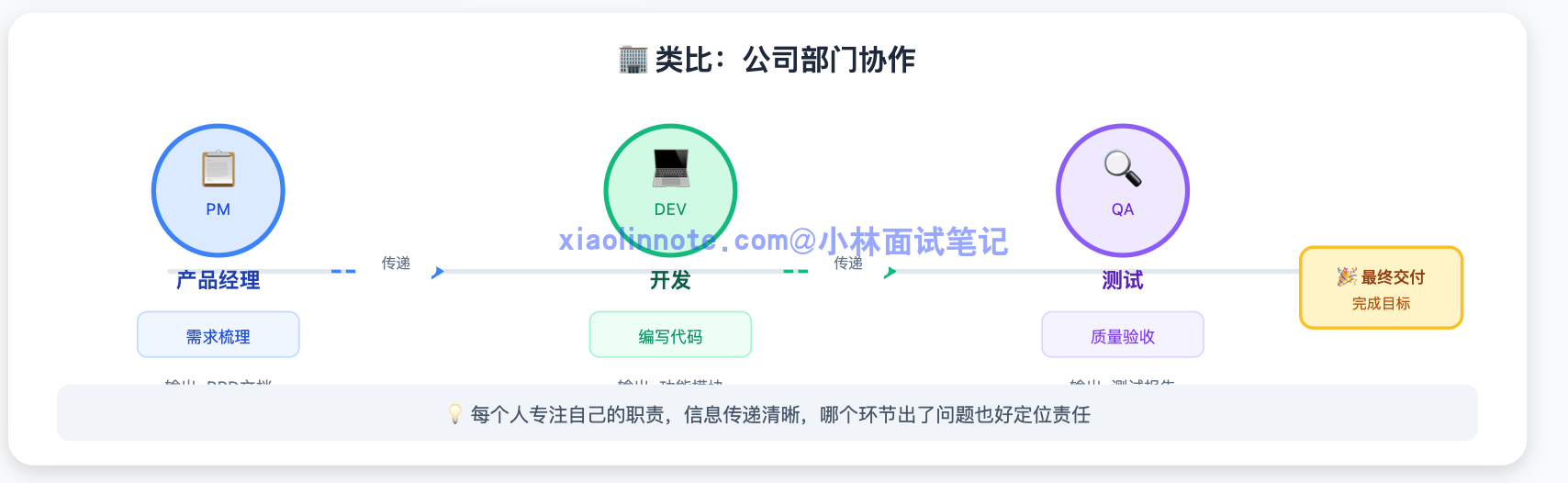
就像公司里的部门协作:产品经理负责需求梳理、开发负责写代码、测试负责验收,每个人专注自己的职责,信息传递清晰,哪个环节出了问题也好定位责任。Multi-Agent 系统就是把这套分工思想搬到 AI 里。
还是以「开发一个爬虫工具」为例,来感受一下两种做法的差距。
不用 Multi-Agent 的情况:一个 Agent 接到任务,同时在想需求文档、代码结构、测试策略,context 里塞满了各种信息,思路乱成一锅粥,写出来的东西哪块都不够好,而且任何一步失误都得从头来。
用了 Multi-Agent 的情况:
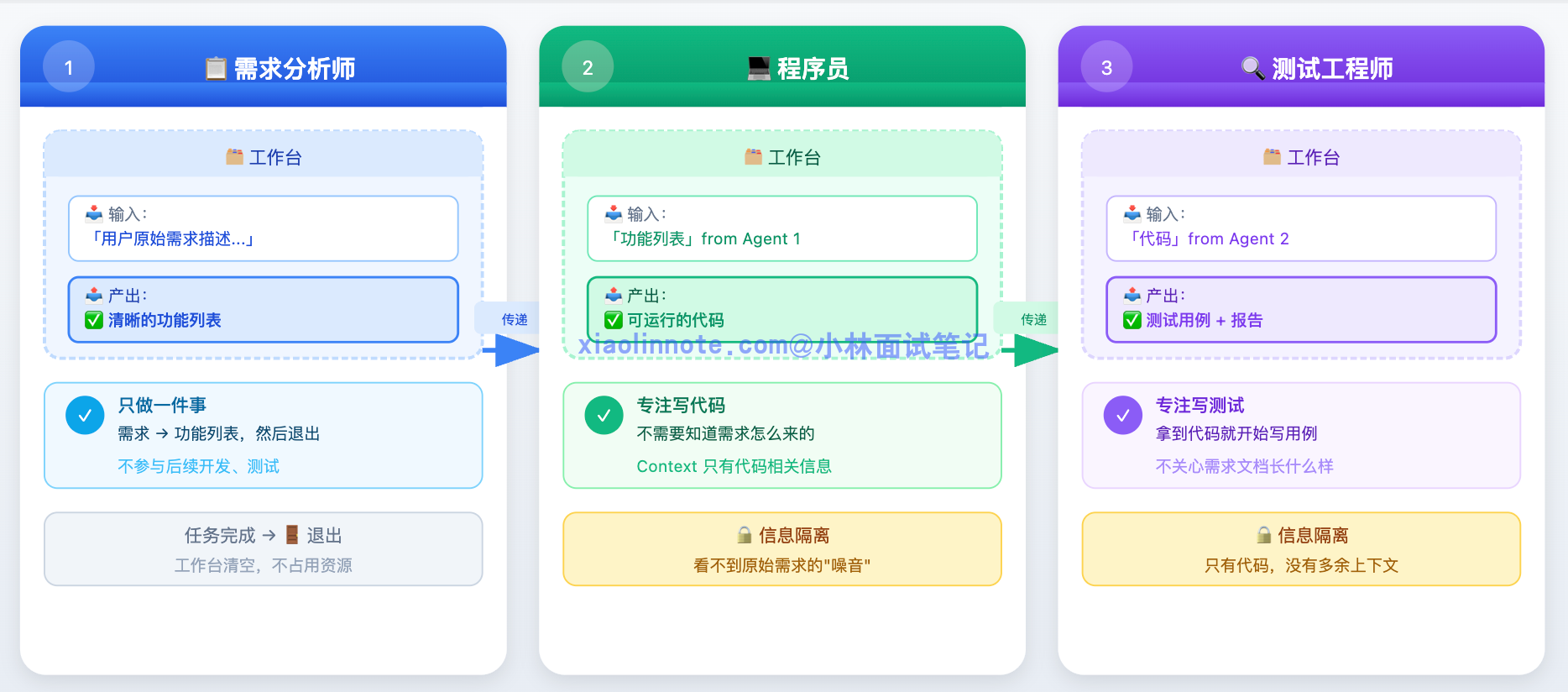
- 第一个 Agent 是「需求分析师」,它只做一件事,把用户需求转化成清晰的功能列表,输出之后就完成使命,退出了,它的工作台是干净的;
- 第二个 Agent 是「程序员」,拿到功能列表,专注写代码,不需要知道需求是怎么来的,context 里只有代码相关的信息;
- 第三个 Agent 是「测试工程师」,拿到代码,专注写测试用例……每个 Agent 的工作台都很干净,只有自己这块任务相关的内容,专业度也更高。
更关键的是,需求分析这步结束之后,程序员 Agent 和测试 Agent 其实可以并行工作,测试框架的搭建不需要等代码写完,两件事同时进行,整体速度也快了。
Multi-Agent 系统的组织方式主要有两种:一种是中心化,由一个统一的调度者来分配任务、收集结果;另一种是去中心化,Agent 之间自行协商、直接通信。这两种方案各有取舍,下一题会展开讲。
10. 说说 Single-Agent 和 Multi-Agent 的设计方案?
💡 简要回答
Single-Agent 适合任务流程清晰、复杂度适中的场景,实现简单、好维护;Multi-Agent 适合需要专业分工、任务量大或者需要并行执行的复杂场景。Multi-Agent 架构上主要有两种拓扑:中心化的 Orchestrator 模式,由一个主 Agent 统一调度各个 Worker;去中心化的 Peer-to-Peer 模式,Agent 之间直接通信。我在工程里用中心化用得更多,因为好控制、好调试,出问题链路清晰。
📝 详细解析
这道题的核心问题是:什么情况下用 Single-Agent 就够了,什么情况下必须上 Multi-Agent,而 Multi-Agent 又该怎么组织?这是实际工程里最常碰到的架构决策,选错了要么系统过度复杂难以维护,要么能力不够任务跑不起来。
Single-Agent
先把 Single-Agent 说清楚。它的本质是一个 LLM 加上一套工具,跑一个决策循环:LLM 判断下一步该做什么,调用工具执行,拿到结果,再判断,直到任务完成。它最大的优势不只是「架构简单」,更核心的是「整条任务链路完全在你掌控之内」。任务怎么走、用什么工具、什么时候结束,所有逻辑都是你在一个地方写清楚的,出了问题链路短,好排查。类比一下:一个人完全可以独立完成「写一篇博客」,自己查资料、想大纲、写下来,不需要团队协作,单人反而更高效,沟通成本为零。
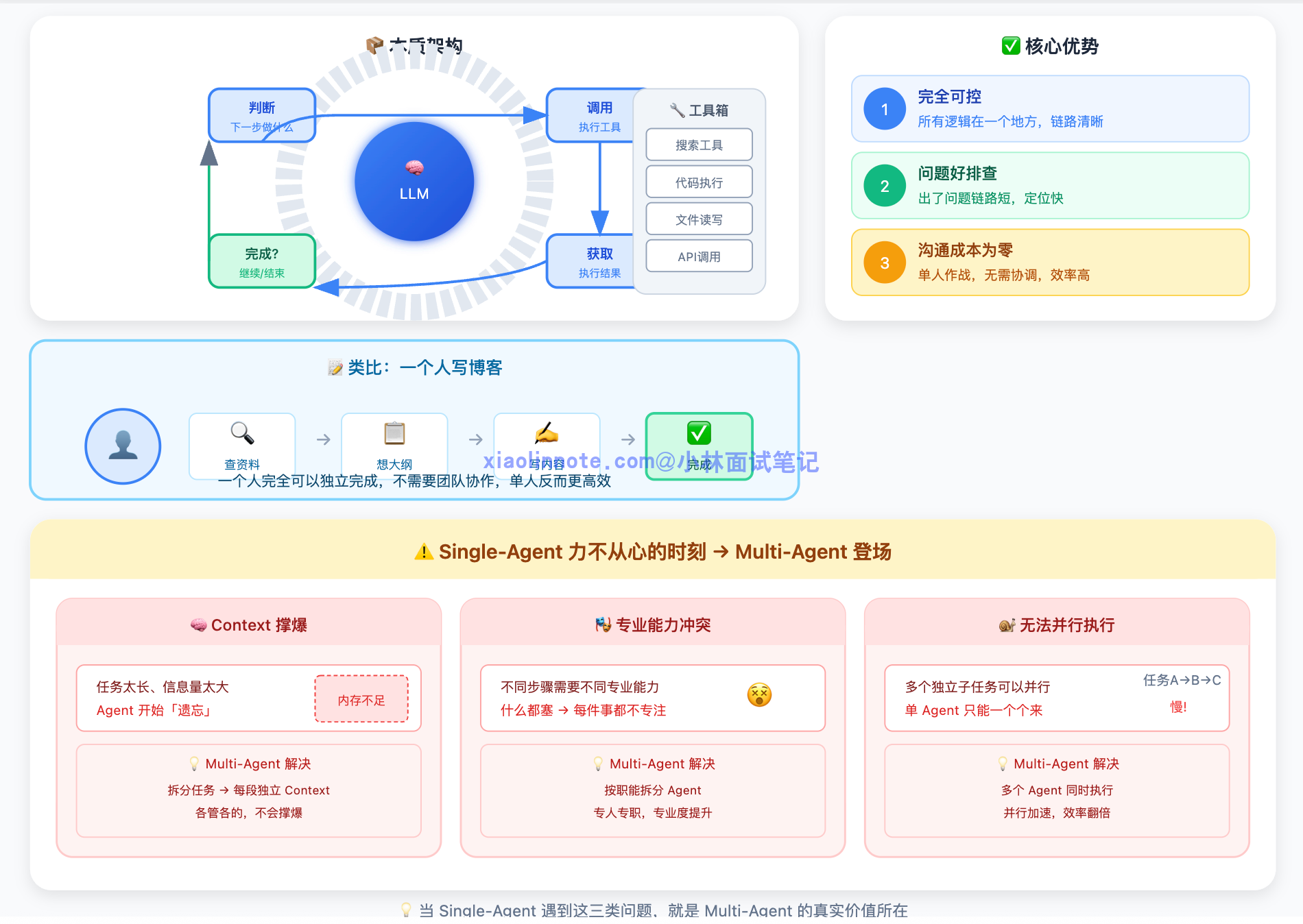
Single-Agent 真正开始力不从心,是在遇到这几类任务的时候:任务太长、信息量太大,context 撑爆,Agent 开始遗忘;不同步骤需要完全不同的专业能力,什么都塞进一个 Agent,每件事都做得不够专注;任务中有多个独立子任务,理论上可以并行,但单 Agent 只能一个个来。遇到这三类情况,Multi-Agent 就有了真实价值。
但需要强调的是:如果你的任务不属于这三类,Single-Agent 就够了,不要为了「用新技术」而强行引入 Multi-Agent,系统会变复杂、变难维护,但没有带来对应的收益。
Multi-Agent 的中心化方案
Multi-Agent 的中心化方案,核心是一个叫 Orchestrator 的特殊角色。「Orchestrator」直译是「交响乐指挥」,在 Multi-Agent 系统里,它的中文可以理解成「总调度员」或「项目经理」。它是整个系统里最特殊的那个 Agent,因为它不做任何具体工作,它只负责三件事:读懂用户的大目标、把它拆成一个个子任务;判断每个子任务该交给哪个 Worker Agent 去做;收集每个 Worker 的产出,把它们拼成最终答案。
相对的,Worker Agent 就是「执行者」。每个 Worker 只关注自己那块,它不需要知道整体任务是什么,不需要知道其他 Worker 在做什么,只需要拿到属于自己的那部分指令,做完返回结果,然后退出。它的 context 是干净的,只装着和自己职责相关的信息。
用一个具体任务来走一遍完整流程,帮你真正理解 Orchestrator 是怎么工作的。假设用户说「帮我写一份 AI 行业竞品分析」:
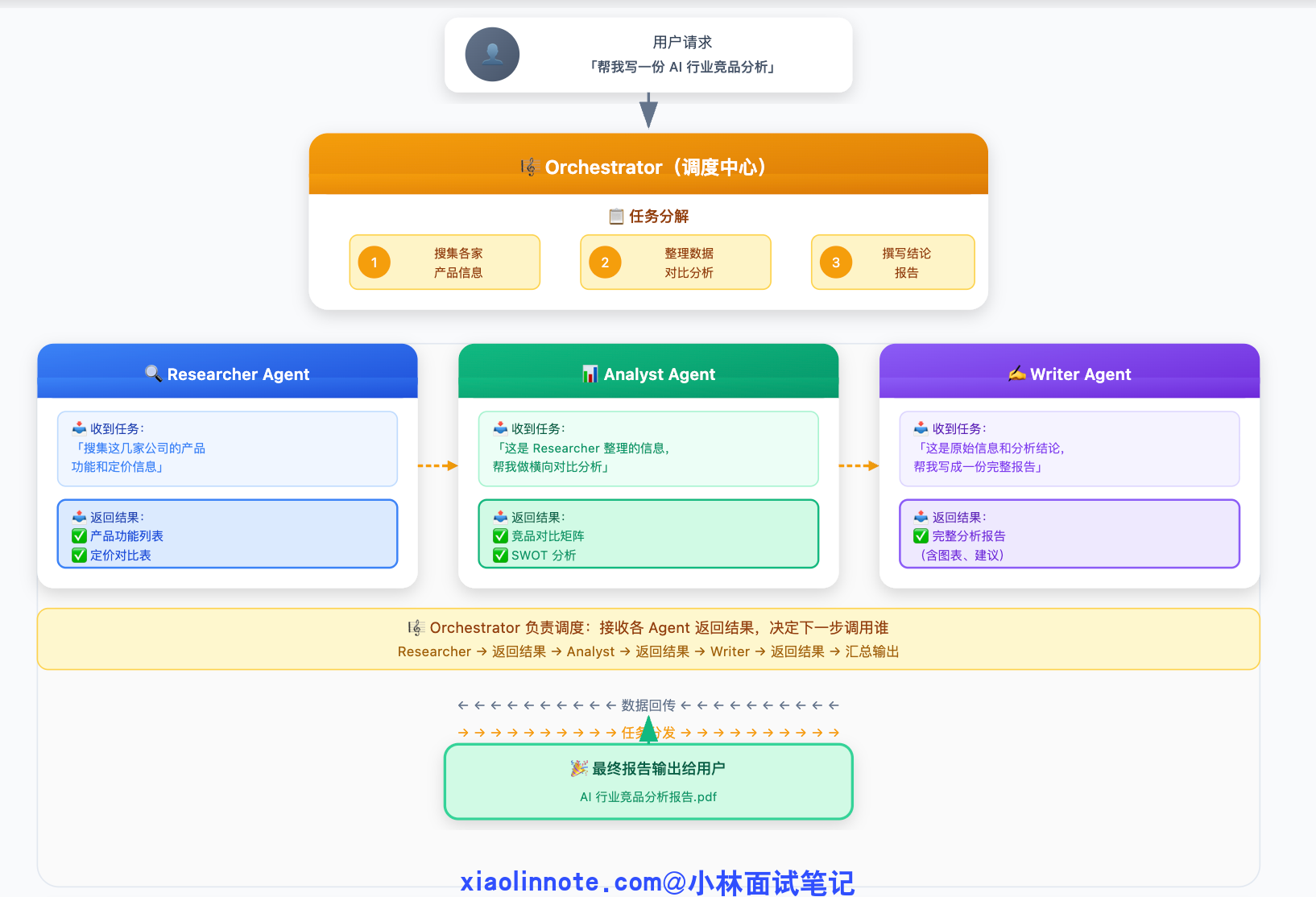
这个流程最大的好处,是每个环节出了问题,你能精准定位。报告内容不够准确?可能是 Researcher 搜的信息不够好。分析逻辑有问题?可能是 Analyst 的对比维度不对。报告格式不符合要求?是 Writer 的输出问题。每个 Agent 职责清晰,排查不需要猜,顺着 Orchestrator 的调度记录一步步追下去就能找到根源。
去中心化方案:为什么「听起来更灵活」却很少在工程上用
去中心化的思路是没有总调度,多个 Agent 通过共享的消息队列或状态空间自行协商、直接通信。听起来很美好,像一个能自我组织的团队,不需要领导,大家自动配合,还更灵活。
但实际工程里会遇到什么问题?用一个具体场景来说明。
假设三个 Agent 在处理同一个任务:Agent A 在搜索信息,Agent B 也在搜索类似的信息,Agent C 负责汇总结果,但没有人统筹调度。这时候几个问题会同时出现:首先,没有人告诉 A 和 B 「你们各搜什么范围」,很可能两个人搜了大量重叠的内容,做了重复工作;其次,C 需要等 A 和 B 都搜完才能汇总,但没有人告诉 C「A 和 B 什么时候算搜完了」,C 不知道该等多久,也不知道有没有漏掉某个 Agent 的结果;再者,如果 A 中途出错了,没有中央调度者收到错误通知,B 和 C 可能还在正常运行,最后汇总出来的是一份不完整的结果,但系统甚至不知道这里出了问题。
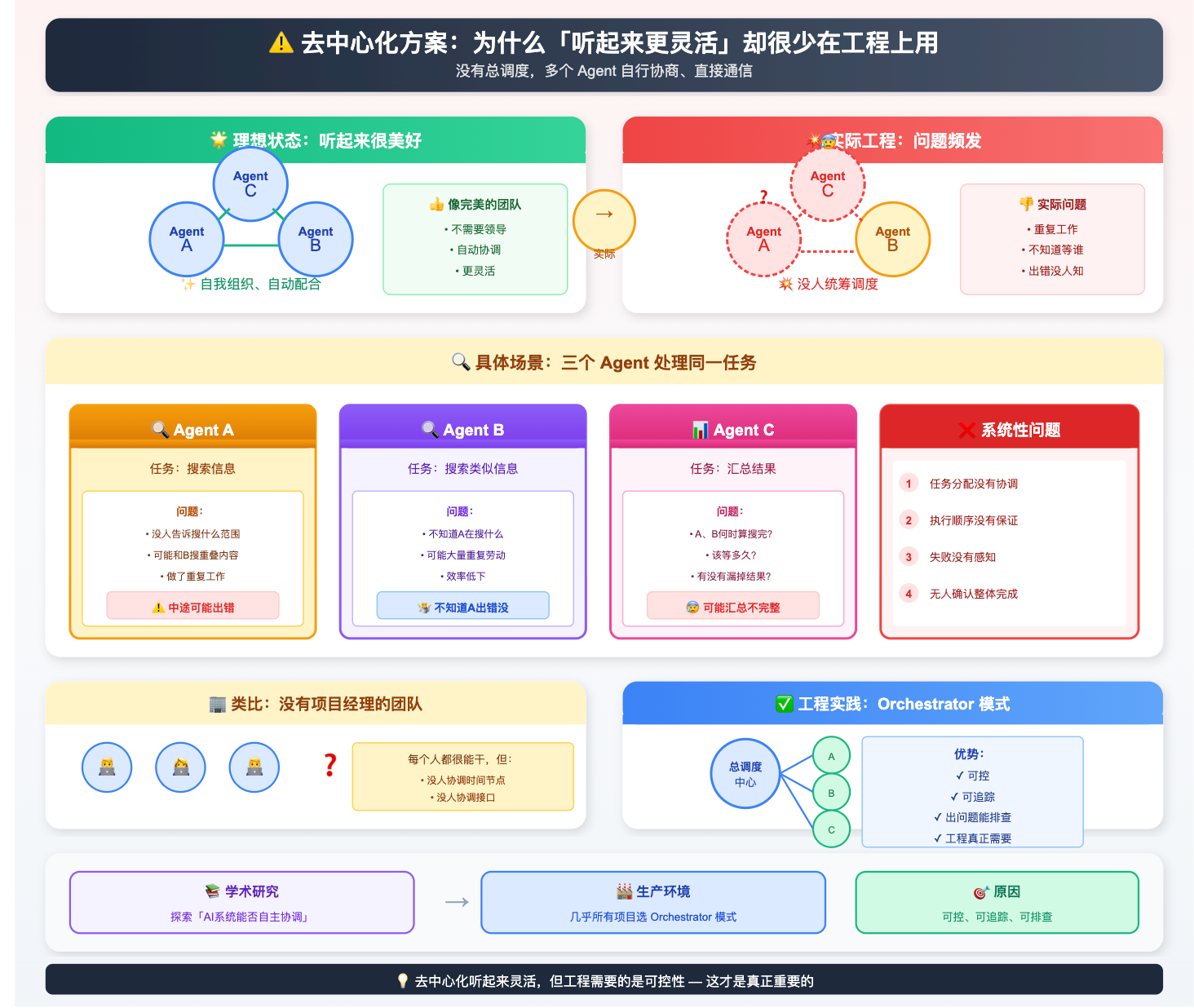
总结下来,去中心化系统里这几类问题会频繁出现:任务分配没有协调、执行顺序没有保证、失败没有感知、没有人来确认「任务整体完成了」。类比一个没有项目经理的团队:每个人都很能干,但没有人协调时间节点和接口,最后交出来的可能是互不兼容的结果,而且没有人知道整体进度到底怎么样了。
这就是为什么去中心化方案更多停留在学术研究里探索,研究的是「AI 系统能不能实现自主协调」这个更宏观的问题。而生产环境里,几乎所有正经项目都选 Orchestrator 模式,因为可控、可追踪、出了问题能排查,这才是工程上真正需要的。
怎么做选型决策?
选型的逻辑其实可以用两个问题来搞定。
先问第一个问题:你的任务,Single-Agent 能搞定吗?如果任务流程明确、不太长、不需要多种专业分工,Single-Agent 就够了。架构简单、维护成本低、链路透明,不要为了「显得高级」而引入 Multi-Agent。
如果任务确实超出了 Single-Agent 的边界,再问第二个问题:你能接受系统行为不可控的风险吗?生产环境里这个问题的答案几乎一定是「不能」,所以就用 Orchestrator 模式。
把三种方案放在一起对比,选型时一眼就能看清差异:
| 维度 | Single-Agent | Multi-Agent(中心化) | Multi-Agent(去中心化) |
|---|---|---|---|
| 架构复杂度 | 低 | 中 | 高 |
| Context 压力 | 全部压在一个 Agent | 各 Agent 独立管理 | 各 Agent 独立管理 |
| 专业能力 | 泛才,什么都做 | 专才分工,各有专责 | 专才分工,各有专责 |
| 并行能力 | 不支持 | 支持子任务并行 | 支持并行 |
| 可控性 | 高 | 高,Orchestrator 统管 | 低,难以统一调度 |
| 调试难度 | 容易 | 中,按调度链路追踪 | 难,行为不可预测 |
| 工程实用性 | 高 | 高 | 低,主要用于学术研究 |
| 适用场景 | 任务清晰、复杂度适中 | 需要分工或并行的复杂任务 | 学术探索场景 |
11. Agent 记忆压缩通常有哪些方法?
💡 简要回答
记忆压缩常见有四种方法:摘要压缩、滑动窗口、重要性过滤、结构化抽取。摘要压缩是把长对话总结成简短摘要;滑动窗口是只保留最近 N 轮对话;重要性过滤是打分筛选,只留重要内容;结构化抽取是把关键信息抽成结构化数据存起来。我在实际项目里最常用的是摘要压缩和滑动窗口,而且经常组合用,滑动窗口丢弃前先做一次摘要,尽量不丢重要信息。
📝 详细解析
想象这样一个场景:你在用一个 AI 助手帮你推进一个复杂项目,聊了一个多小时,确认了技术方案、梳理了需求、定下了几个重要决策。然后有一刻,AI 突然开始「忘事」了,把你早就敲定的方案搞错,重新提出已经被你否决的思路。你感觉很困惑,明明刚才还在聊,它怎么就不记得了?
这个现象的根源,就是 context window 的限制。
LLM 每次生成回答,并不是像人脑一样有持续的记忆,它依赖的是「每次调用时传入的完整对话历史」。你和它聊的每一句话,都被打包成 messages 列表传进去,模型读完这些内容,才能生成下一条回复。这个 messages 列表是有硬上限的,GPT-4o 是 128K token,Claude 是 200K token,超过了就得截断。默认的截断策略是「从最老的对话开始丢」,于是那个三十分钟前确认的技术方案,就这么被扔掉了。
更现实的压力还有成本。就算没有超过 token 上限,对话越长,每次调 LLM 的费用就越高,因为你把越来越多的历史塞进了输入。高频使用场景下,这是货真价实的成本压力。
记忆压缩要解决的,就是「空间有限、成本有压力」这两件事:在保留关键信息的前提下,减少历史记录占用的 token 数量。
第一种方法:滑动窗口,最简单的方案,也是最粗糙的
滑动窗口是最符合直觉的做法,就像手机聊天记录默认只显示最近 200 条:超出就从最老的开始删,只保留最近 N 轮对话。
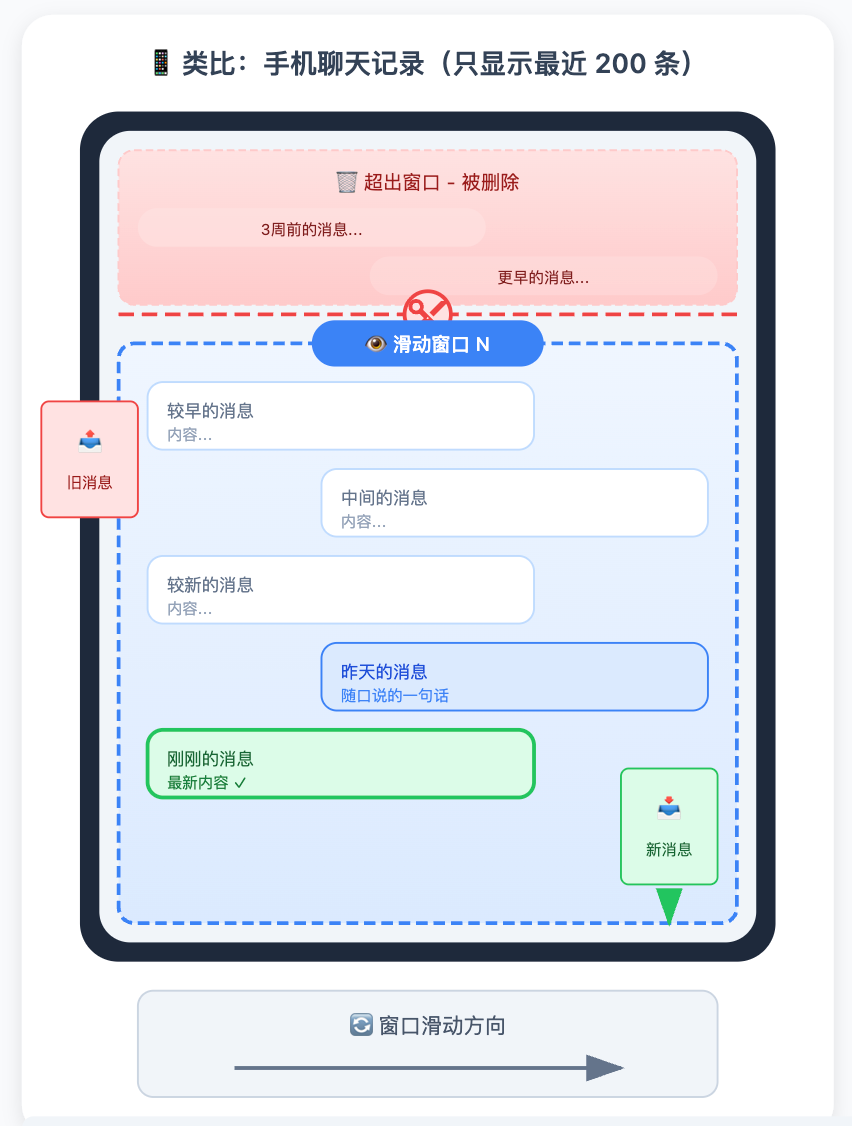
好处是实现极其简单,不需要任何额外的 LLM 调用,也没有额外开销。坏处是「硬截断」,对话内容按时间一刀切,三周前确认的关键决策和昨天随口说的一句话,在这个方案里是被同等对待的,超出窗口就都消失了。
可以用一个词概括它的特性:「金鱼记忆」。它只记得最近发生的事,越往前越模糊,再久一点就什么都没了。对于短对话、或者历史信息不重要的场景,这个方案足够用,成本最低。
第二种方法:摘要压缩,丢之前先提炼一遍
摘要压缩是对滑动窗口「硬截断」的改进。核心思路是:不直接丢弃即将超出窗口的历史,而是先让 LLM 把这段历史总结成一段精华摘要,用摘要替换原始对话,再继续往前。
类比一下:你的笔记本快写满了,你没有把前面的页直接撕掉,而是先把前半本的要点重新整理成一页纸的精华总结,然后把前半本收起来,带着这页总结继续记录后面的内容。后来翻回去看,这页总结虽然不如原版详细,但关键脉络都在。

代价是摘要会丢失细节。LLM 在总结时,会按照自己判断的「重要性」来决定保留什么、省略什么。有些细节当时看起来不重要、被摘要略过了,后来却刚好需要,这时候就找不回来了。
这个方案单独用时,通常的做法是「旧的压缩成摘要,近的保持完整」,最近几轮对话往往和当前任务关系最密切,保持原文;更早的历史相关性低,压缩成摘要。
最常见的工程组合:滑动窗口 + 摘要
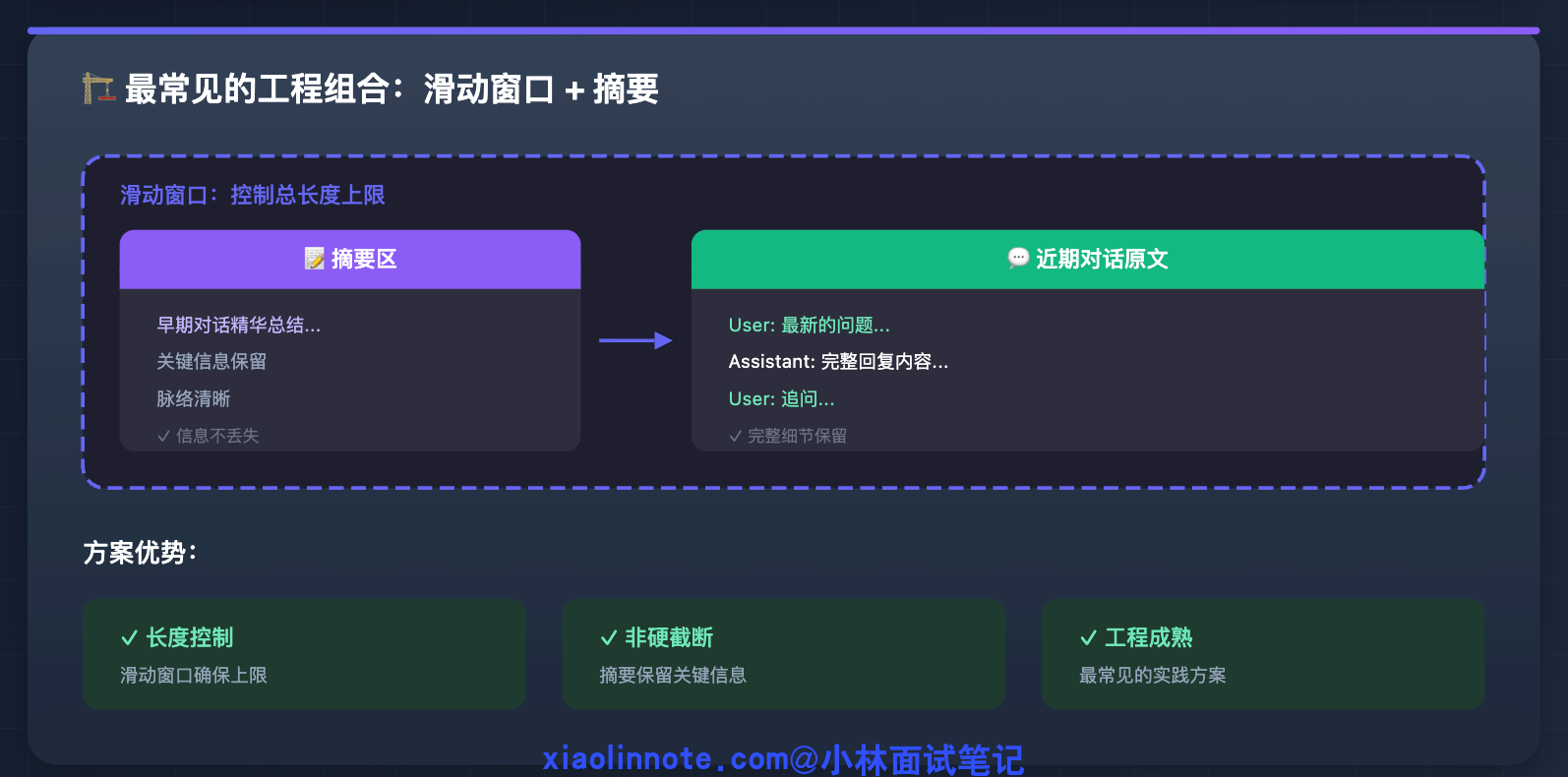
在实际工程里,这两种方法通常一起用,而不是单独用其中一种。滑动窗口负责控制对话历史的总长度上限,摘要压缩负责在历史被丢弃之前做一次提炼,把关键信息留下来。这样既有长度控制,又不是直接硬截断,是目前最常见的工程方案。
第三种方法:重要性过滤,按价值筛选,不按时间筛选
滑动窗口和摘要压缩有一个共同的思路:都是在「时间维度」处理历史,按照发生的先后顺序来决定保留什么。但时间不等于重要性。三周前的一句关键决策,可能远比昨天的几句闲聊更有价值,但在滑动窗口里它会先被丢掉。
重要性过滤换了一个角度,按内容的实际价值来决定去留:给每条对话记录打一个重要性分数,低于阈值的淘汰,高分的保留。
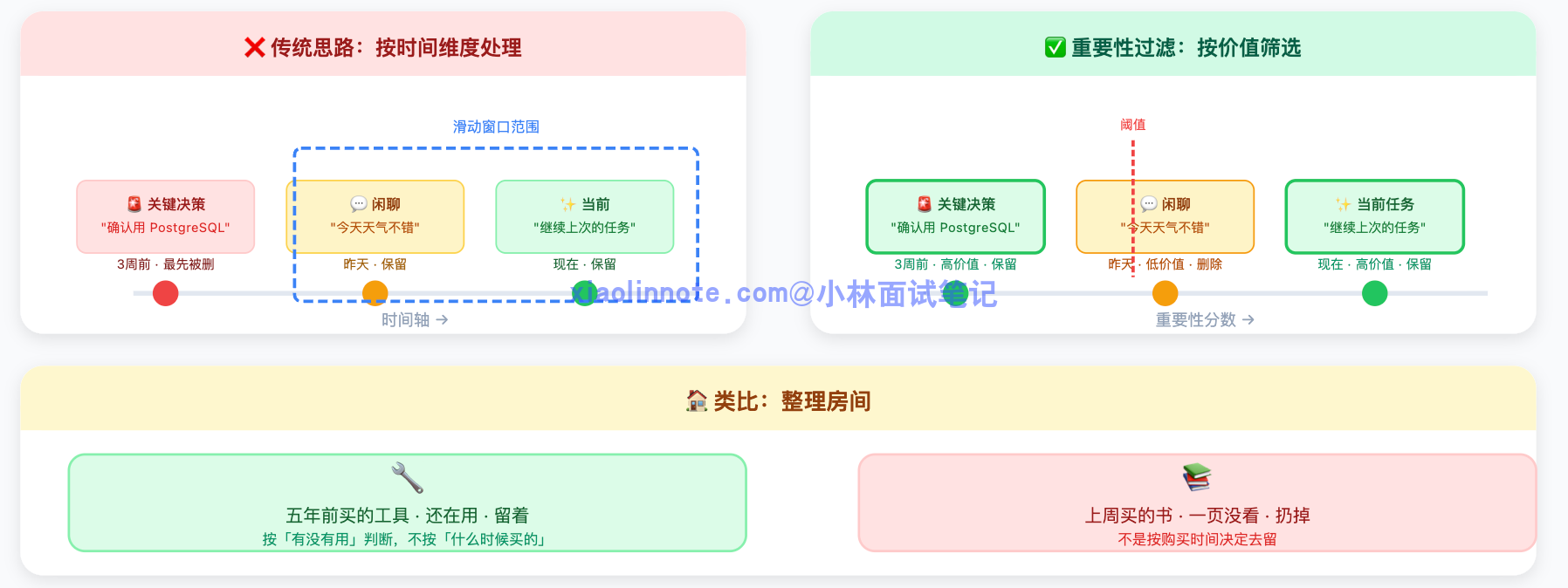
类比整理房间:一个人不会按照购买时间来决定扔什么东西,而是按照「这个东西现在还有没有用」来决定去留。一件五年前买的工具,如果还在用,就留着;一本上周买的书,如果一页没看还不打算看,就可以扔。
打分的方式有两种。一种是规则打分:包含「决定」「确认」「需求」等关键词的记录加分,被后续对话引用次数多的加分,纯闲聊降分。规则快、没有额外开销,但比较粗糙,边界情况容易判断失误。
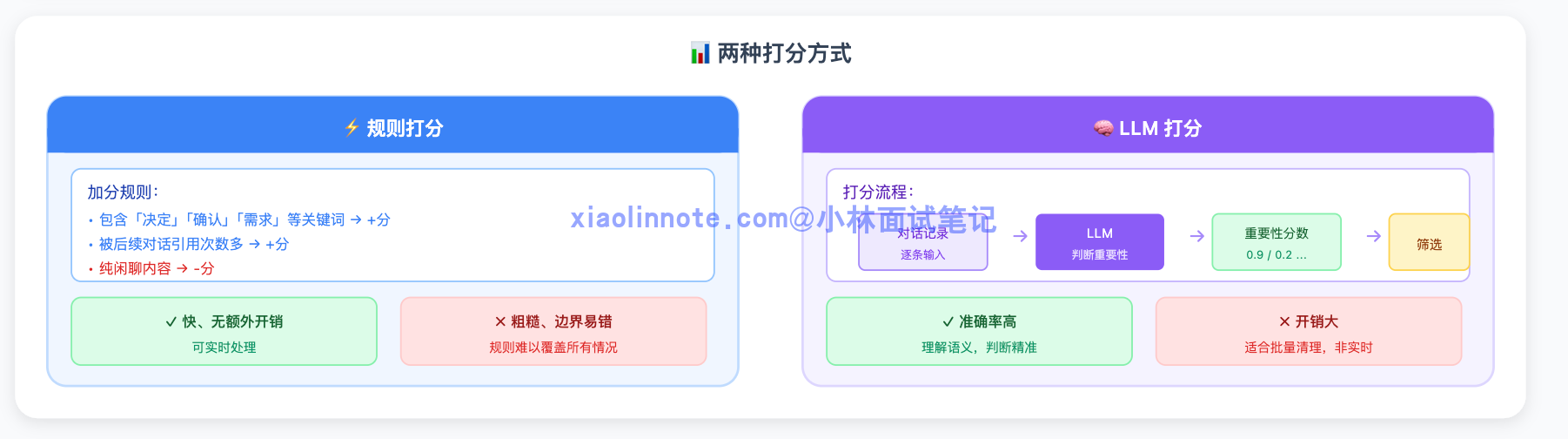
另一种是让 LLM 来打分:逐条判断每条记录的重要程度。准确率更高,但每条记录都需要一次 LLM 调用,开销大,通常在批量清理历史时做,而不是实时处理每条消息。
第四种方法:结构化抽取,换一种载体存信息
前三种方法有一个共同的前提假设:历史信息最好以「对话文本」的形式保留。结构化抽取的思路完全不同,它先问一个更本质的问题:我们真的需要保留对话文本本身吗?
很多场景里,真正有价值的不是对话文字,而是对话中传递的事实和状态。比如「用户偏好用 Python」「预算上限是 5 万」「已确认方案 B」「需要兼容移动端」。把这些信息主动提取出来,存成结构化字段,后续注入 prompt 时直接用这些字段,比传一大段对话文本要高效得多,信息密度也高得多。
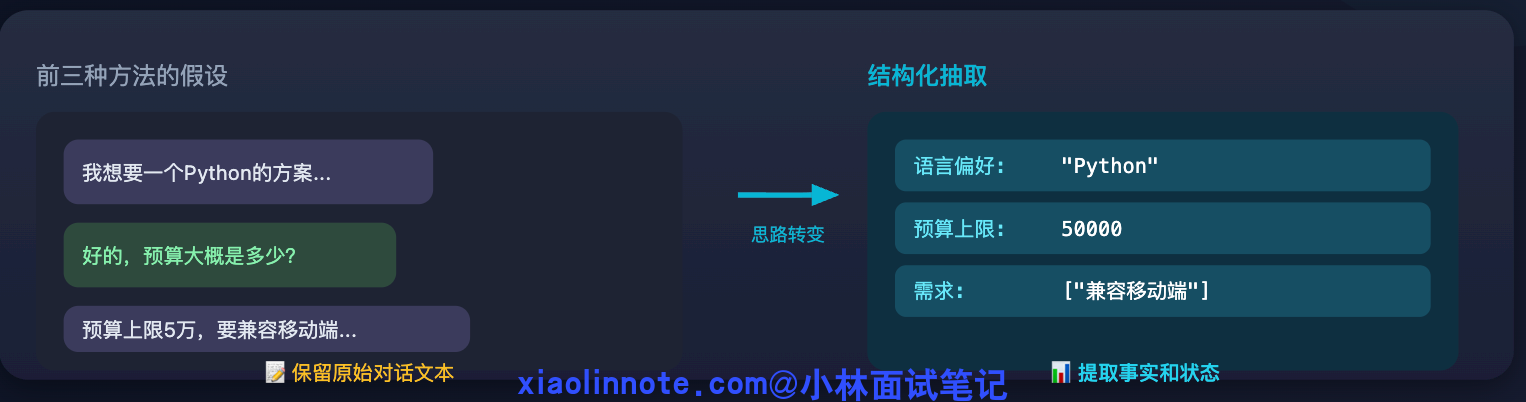
类比医生记录病历的方式:医生不会把和病人的所有对话逐字记录下来,而是整理成结构化的病历档案,「主诉:头痛三天,现病史:无发热,过敏史:青霉素,初步诊断:紧张性头痛」。这份档案的信息密度远高于原始对话文字,下次就诊时医生直接读病历,不需要把上次的全程录音重听一遍。

这种方案的信息损失最小,只要字段定义合理,重要信息全部被精确保留,没有摘要带来的模糊化。代价是开发成本最高:你需要预先定义「什么是重要字段」,这需要对业务场景有深入理解,而且不同类型的任务所需的字段可能完全不同,通用性较低。
四种方法的关系梳理
这四种方法不是互斥的,也不是按优劣排列的,而是从三个不同维度来解决问题的。
滑动窗口和摘要压缩解决的是「历史太长,怎么截」的问题,前者直接截,后者截之前先提炼。重要性过滤解决的是「内容不等价,怎么挑」的问题,打破时间顺序,按价值筛选。结构化抽取解决的是「对话文本本身是不是最佳载体」的问题,换一种更高效的形式来存储信息。
这三个维度可以组合:比如先用重要性过滤筛掉低价值内容,再用摘要压缩处理剩余历史,同时对特定类型的关键信息做结构化抽取。实际系统里,往往是多种方法配合使用的。
Prompt Caching:在「计算层」的互补手段
除了上面这些「信息层」的压缩策略,还有一个工程上值得了解的技术叫 Prompt Caching,Anthropic 的 Claude 和 OpenAI 都已支持。
理解它之前,先知道一个背景:LLM 每次处理请求,都需要把输入的所有 token「过一遍模型」来做计算,这个过程叫 prefill,是延迟和成本的主要来源之一。一个常见的场景是:你有一段固定的 system prompt 加上越来越长的对话历史,每次调用时这段历史都会被重新计算一遍,哪怕它和上一次调用时完全一样。
Prompt Caching 的思路是:如果 prompt 的前缀部分在多次请求之间是一样的,就把这部分的计算结果缓存起来,下次请求如果前缀匹配,直接复用缓存,不重新计算。费用和延迟都大幅降低,某些场景下能降到原来的十分之一。
这和前面的记忆压缩是两个不同层次的优化。记忆压缩在「信息层」工作,决定哪些内容值得被保留在对话历史里;Prompt Caching 在「计算层」工作,对已经决定要带进去的内容减少重复计算的开销。两者解决的不是同一个问题,可以同时使用,是互补关系,不是替代。
工程实践决策参考
选方案的时候,可以按这个思路来判断:对话不长、业务简单的场景,滑动窗口就足够了,实现成本最低;对话会很长但不想硬截断的场景,摘要加滑动窗口的组合是最稳健的工程选择;如果业务里有明确定义的「关键信息」(用户偏好、确认事项、状态字段),结构化抽取的信息密度最高,效果也最好;高频调用、长 prompt、成本敏感的系统,Prompt Caching 的收益非常可观,值得优先考虑。
12. 在工程实践中,为什么有时候选择「手搓」Agent,而不是直接用成熟框架?
💡 简要回答
我的感受是框架用起来快,但有几个实际痛点。第一是抽象层太多,调试的时候不知道哪步出了问题,得一层层往下扒;第二是版本升级经常有破坏性变更,线上稳定性难保证;第三是框架的通用设计往往和具体业务需求有偏差,定制起来反而更费劲。手搓的代码完全在自己掌控之内,可观测性好、出问题好排查,也更方便做性能优化。所以我现在的策略是核心逻辑手写,只在边缘功能上用框架的工具。
📝 详细解析
想象一下,你从零开始搭一个 Agent。你需要定义工具的格式,让 LLM 能正确理解每个工具是什么、需要哪些参数;你需要解析 LLM 返回的工具调用结果;你需要在每次调用之间正确维护对话历史,不能丢消息也不能顺序错;你需要处理工具调用失败时的重试逻辑;你可能还需要接入向量数据库做知识检索……这些事情,每一个 Agent 项目都得做一遍,而且大同小异。
框架的价值就在这里:把上面这些重复工作全部封装好,你直接用,不用每次都造轮子。
LangChain 里一个 @tool 装饰器就能注册工具,AgentExecutor 把整个 ReAct loop 封装进去,还内置了 tracing、callback、记忆管理。早期上手快是真实的优势,两周的工作缩短到两天,特别是在快速验证 idea 的阶段,框架几乎没有明显的副作用。
痛点在什么时候开始出现?
框架的问题不是一开始就暴露的,而是随着项目推进,在不同阶段逐渐浮出来的。
探索期,框架真的很爽。你在做 POC,目标只是把流程跑通,几乎感受不到任何副作用。LangChain 帮你省掉了大量样板代码,几十行就搭起一个能用的 Agent,心情很好。
第一个奇怪的 bug 出现之后,感觉就变了。Agent 在某个特定场景下输出了错误的工具参数,你开始排查。代码只有五十行,但报错的 stack trace 有四十层,往下追到了框架内部。你不知道问题出在你写的那五十行里,还是框架某个版本的逻辑变化,或者是 callback 触发时机的问题。你开始在 GitHub issue 里搜,或者一层层读框架源码。
类比一下:老式车出了问题,打开引擎盖自己就能看到哪根管子漏油;现代豪华车出了问题,你打开引擎盖看到的是一堆你看不懂的电子设备,只能去 4S 店让诊断仪扫。框架的抽象层太多,排查问题需要穿透那些你没写、也不完全懂的层,这是实实在在的认知负担。
版本升级踩坑,是另一个阶段的痛苦。线上跑了几个月,某次依赖升级,LangChain 改了接口,代码直接报错。你要么回滚,要么把代码改到兼容新版本,可能涉及十几处修改。LangChain 早期版本升级频率很高,breaking change 是常见的。把核心业务逻辑建立在一个变动频繁的第三方框架上,线上稳定性就会受到这种不确定性的影响。
性能优化时发现了隐性开销,是到了规模化阶段才会碰到的问题。你开始关心 Agent 的调用延迟,发现某步 LLM 调用本身很快,但总耗时超预期。仔细 profile 之后,发现框架内部在每次调用时做了你根本不需要的事:序列化中间结果、触发一堆 callback、记录详细日志……这些逻辑是框架为了通用性设计进去的,对你的具体场景没有用,但每次调用都在跑。高流量下这些隐性开销累积起来,变成真实可见的延迟增加和费用浪费。
手搓的本质优势:完全掌控
说清楚框架的痛点之后,手搓的价值就容易理解了。它的核心优势,就是「完全掌控」三个字,体现在三个层面。
第一是链路透明、可观测性好。手搓的每一行代码你都知道在干什么,可以在任意位置加日志、打断点、插入监控,没有任何黑盒。线上出了问题,靠日志复现故障是最快的方式,链路越清晰,定位根因越快。这在生产环境里,是真实的时间和成本节省。
第二是精确裁剪、没有多余开销。你只写你确实需要的逻辑,不带任何通用性包袱。工具调用、对话历史维护、错误重试,每一块都按照你的具体场景来实现,没有为了「兼容其他用法」而存在的冗余逻辑。在性能敏感的场景里,这意味着优化空间完全在自己手里,不用绕过框架的限制来做裁剪。
第三是稳定可控、不受框架升级影响。你自己写的接口不会突然变,没有来自外部的 breaking change。依赖只有底层的 LLM SDK,相对稳定,生产环境可以长期运行,不用担心某次例行的依赖升级把线上跑坏。
有一个类比能很好地概括这个区别:框架是「租房」,装修好直接住,方便,但结构改不了,房东随时可能调整政策;手搓是「自建」,建起来慢,但所有结构都熟悉,改什么都能改,住着踏实。框架给你省了搭建时间,但你对这个「房子」的控制权始终有限。
什么时候用框架,什么时候手搓?
这不是非此即彼的选择,判断的关键是项目所处的阶段和对控制权的需求。
框架适合的时机:POC 阶段快速验证 idea,目标是跑通而不是优化;团队刚接触 Agent 开发,用框架能少踩一些基础性的坑;周边工具(文档解析、向量检索)依赖框架的生态,核心逻辑本身复杂度不高。这些场景里,框架带来的速度优势是真实的,值得用。
手搓的时机:准备上生产,稳定性成为核心关切;流量开始上来,性能和成本变得敏感;业务逻辑高度定制,和框架的通用设计偏差很大,改起来反而麻烦;团队需要高可观测性,链路要能随时监控和回溯。
折中方案:核心手写,周边借用
实践中最常见也最务实的选择,是介于两者之间的折中:核心逻辑手写,周边工具性功能借用框架。
控制边界的逻辑是这样的:工具调用的循环、对话历史的管理、错误处理和重试、任务状态的维护,这些是 Agent 的「心脏」,直接决定系统行为,必须百分百理解、百分百掌控,所以手写。而 LangSmith 的 tracing(调用链追踪)、LlamaIndex 的文档解析、某个向量库的 Python 客户端,这些是「工具性」的周边功能,出了问题一眼就能看出来,不会带来黑盒困境,用外部工具节省时间完全值得。
就像盖房子:自己设计核心结构、承重墙在哪、房间怎么布局,你必须完全掌控;但门锁、插座面板、水龙头,完全可以买现成的,不必自己从头制造每一个零件。
工程实践的清醒视角
最后有一点值得说清楚:手搓不是「比框架更好」,而是「在特定阶段有特定的价值」。
很多真实项目的演进轨迹是这样的:先用框架快速跑通,验证了方向;遇到第一批线上问题之后,开始把排查困难的关键部分替换为手写;流量上来之后,把性能敏感的核心逻辑全部手写;最后,框架只保留做得很好的周边工具。这条路走下来,既享受了早期框架的速度,又在生产阶段拿回了掌控权。
有一个判断信号可以参考:如果你能清楚说出「框架在某个地方替我做了什么、我用的这个方法内部发生了什么」,说明你理解它,用起来有掌控感;如果你只是调了一个方法但完全不知道里面发生了什么,出了问题就是一个不透明的黑盒,这才是需要警惕的信号。框架本身不是问题,「不理解就依赖」才是。
13. 如何赋予 LLM 规划(Planning)能力?
💡 简要回答
CoT、ToT、GoT 这三种我都了解过,给 LLM 加规划能力主要靠这几种思路。CoT 是让 LLM 把推理步骤写出来,线性地一步步推导到答案;ToT 是让它同时探索多条推理路径,选最优的继续深入;GoT 是图结构推理,推理节点可以复用和合并,适合更复杂的任务。工程上我用 CoT 最多,因为实现成本最低,就是改个 prompt;ToT 效果更好但调用次数多,成本大概是 3 到 5 倍;GoT 目前还比较学术,生产环境我没见过有人真正落地用的。
📝 详细解析
要理解为什么需要规划能力,先看 LLM 在没有任何规划机制时是怎么运作的。
普通的问答模式下,LLM 接到一个问题,就直接「一口气」生成答案,中间没有任何推理过程。这对简单问题没啥大问题,但遇到需要多步推导的任务就很容易翻车。比如让它做一道需要 3 步推导的逻辑题,如果直接让它给答案,出错概率会远高于让它把每步都写出来。
背后的原因是 Transformer 的 next-token 预测机制,每个 token 是基于前面所有 token 生成的,推理链越长、隐式的跳步越多,误差就越容易在中间某一步悄悄累积,最后给出一个看起来很自信但其实是错的答案。
「规划能力」要解决的就是这个问题:把 LLM 隐式的推理过程显式化,让它不再是「一步跳到答案」,而是「一步一步推到答案」,每步都有迹可循。
CoT、ToT、GoT 是这个方向上依次演进的三种方案,每一个都在解决前一个的局限性。
CoT:最简单的激活方式,加一句话就够了
CoT 的全称是 Chain of Thought(思维链),核心思路极其简单:在 prompt 里加一句「请一步步思考」,LLM 就会把推理过程逐步写出来,而不是直接蹦出答案。
为什么这么简单的改变就有效?

本质是因为 LLM 的输出是顺序生成的,当它先输出推理步骤,这些推理内容会进入上下文,影响下一个 token 的生成。换句话说,「写下来的推理过程」本身就成为了后续生成的依据,帮助 LLM 不跳步、不乱想。就好比你在纸上演算数学题,把每一步写出来之后,下一步出错的概率会比在脑子里算要低得多,原理是一样的。
CoT 有两种触发方式。
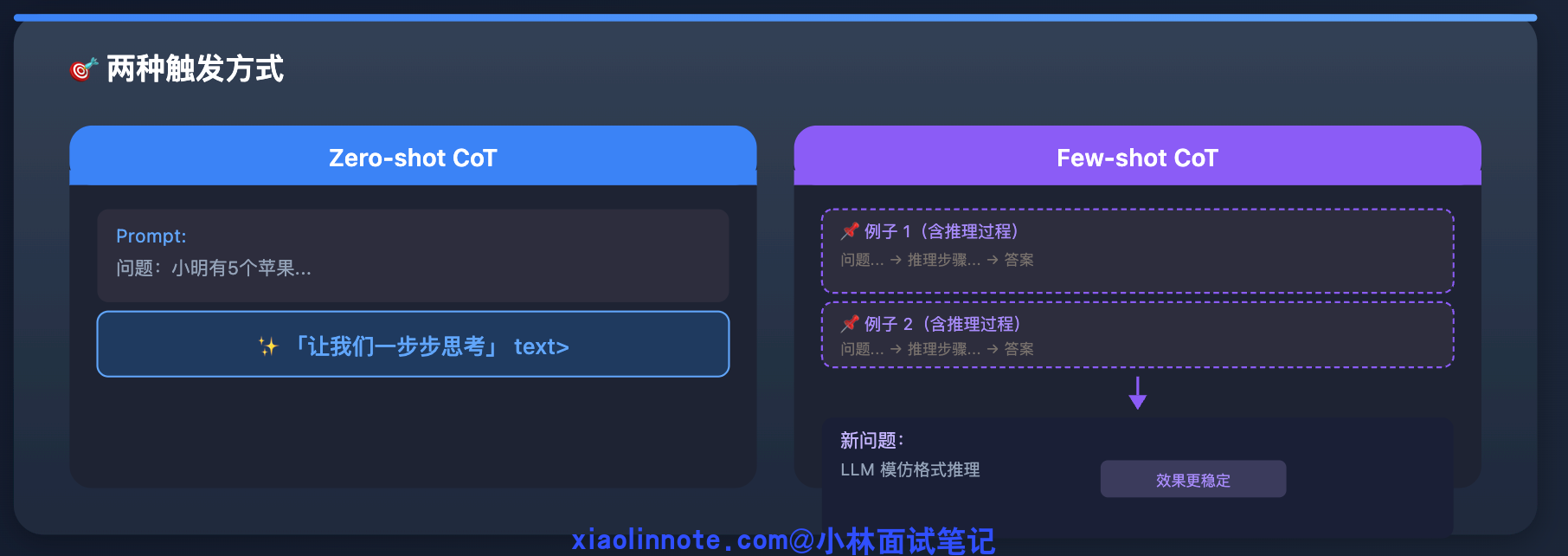
- 第一种叫 Zero-shot CoT,就是直接在 prompt 末尾加「让我们一步步思考」,LLM 自己展开推理,不需要额外例子;
- 第二种叫 Few-shot CoT,给几个带有完整推理过程的例子,让 LLM 模仿这种推理格式来回答新问题,效果通常更稳定。
CoT 的局限很明显:它只有「一条推理路径」。如果一开始走错了方向,整条链就歪了,没有任何纠偏机制。

ToT:从「一条链」到「一棵树」,解决走错方向的问题
ToT 的全称是 Tree of Thoughts(思维树),针对的正是 CoT「一旦走错就全错」的问题。
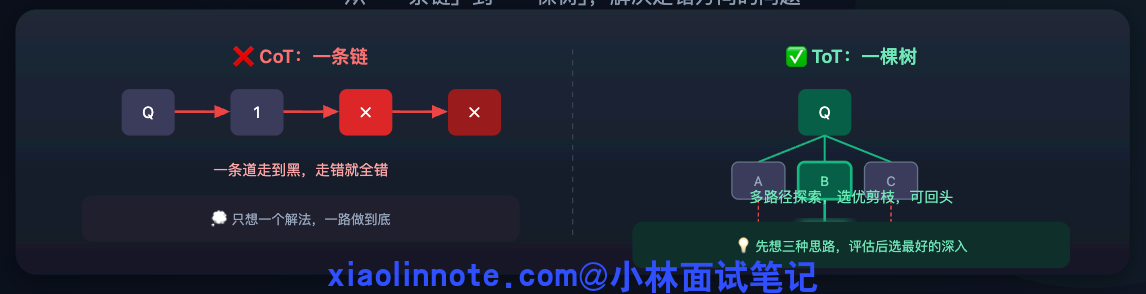
核心改变是把「生成一条推理链」变成「同时探索多条推理路径,边探索边剪枝,最终选出最优路径」。用一个生活类比来理解:CoT 像你做题时只想了一个解法,一路做到底;ToT 像你先想了三种可能的解题思路,评估了一下哪种最靠谱,选了最好的那条继续深入,另外两条直接放弃。
ToT 的执行流程可以分三步来理解。首先是生成多个候选思路,让 LLM 针对同一个问题给出 3 个不同的初步方向,而不是只走一条路。然后是评估每个思路的可行性,用另一个 LLM 调用(或同一个 LLM 带上评估 prompt)给每个思路打分,判断哪个最有希望。最后是选优继续深入、剪掉差的,只保留分数高的思路,再展开下一层推理,反复循环直到得出最终答案。

这个「生成 -> 评估 -> 剪枝」的循环,让 LLM 不再是「一条道走到黑」,而是有了探索多条路、选好的走、发现走错了还能回头的能力。代价也很明显:原来 CoT 一次生成就搞定,ToT 需要多次 LLM 调用(多条路径 × 多层深度 × 每层还要评估),成本是 CoT 的 3-5 倍甚至更高。
GoT:从「树」到「图」,解决推理结果不能复用的问题
GoT 的全称是 Graph of Thoughts(思维图),是在 ToT 基础上再进一步的进化。
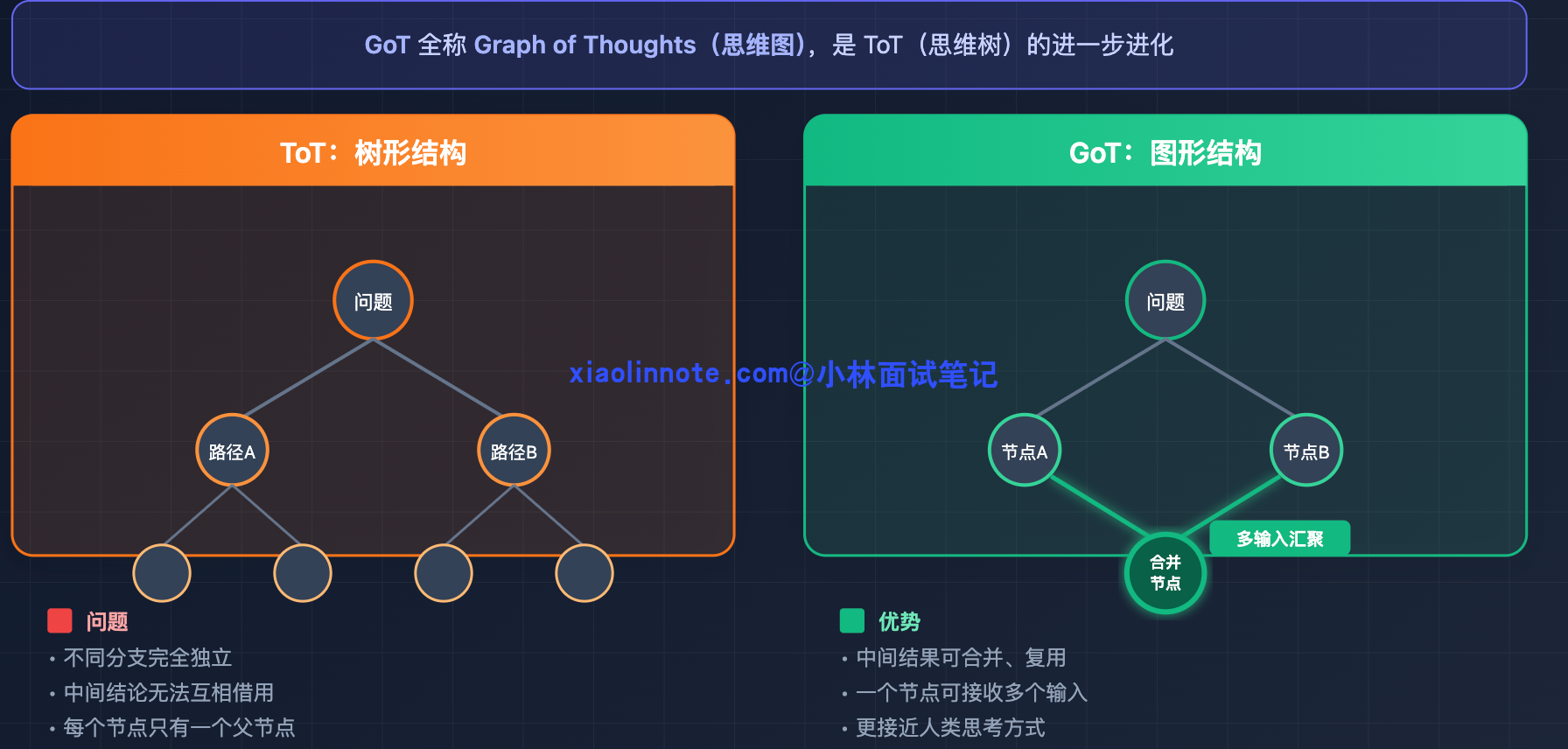
ToT 虽然引入了多路径探索,但它是树形结构,不同分支之间完全独立,两条推理路径上的中间结论无法互相借用。GoT 把推理结构换成了图,允许不同路径的中间结果合并、复用,也就是说一个推理节点可以接收来自多个前置节点的输出作为输入。
举个具体例子:如果任务是「分别研究竞品 A 和竞品 B,然后做综合对比分析」。ToT 里研究 A 和研究 B 是两条独立的路径,各自得出结论;但「综合对比分析」这一步需要同时用到两条路径的结论,在树形结构里很难自然表达,因为树的每个节点只有一个父节点。GoT 的图结构允许把「研究 A 的节点」和「研究 B 的节点」的输出,汇聚到「综合对比分析节点」,这种「多个中间结论合并输入到下一步」的操作在图里是一等公民,表达起来非常自然。
GoT 能建模的推理模式比 ToT 更丰富,也更接近人类实际处理复杂任务的思考方式。但落地复杂度很高,目前主要还是学术研究场景,生产环境里极少见到真正用起来的。
三者的演进关系
把这三者放在演进视角里看,逻辑非常清晰。
CoT 解决了「要不要把推理显式化」的问题,答案是要,把过程写出来就能显著减少跳步出错。
ToT 解决了「走错方向怎么办」的问题,答案是先多探索几条路,边走边评估边剪枝。
GoT 解决了「不同推理路径的中间结论能不能复用」的问题,答案是把结构从树换成图,自然支持结论汇聚与复用。每一步都是在前一步的基础上发现局限、针对性改进。
工程上怎么选?
CoT 几乎是所有任务的标配,加一句话、零成本,直接加到 system prompt 里就行。ToT 在准确率要求很高、任务比较复杂的场景值得考虑,但要做好调用成本增加 3-5 倍的心理准备。GoT 目前工程落地不成熟,主要了解它的思想即可,真实项目里不必强行引入。
14. 讲讲 Agent 的反思机制(Reflection)?为什么要用反思?具体怎么实现?
💡 简要回答
反思机制我的理解是:让 Agent 在完成一个步骤或整个任务后,自我评估输出质量,判断有没有问题,不达标就重试或调整策略。用反思的原因是 LLM 第一次输出不一定是最优的,加一轮自我检查能显著提升质量,相当于人写完东西自己再看一遍。代价是多至少一次 LLM 调用,token 消耗和延迟都会增加,所以我在工程里通常只在质量要求高的关键节点启用反思,不是每步都做。
📝 详细解析
先从一个日常经验说起:你写完一篇文章,扔到一边,过半小时再拿回来读,往往能发现一堆之前没注意到的问题,某个句子逻辑跳跃了、某个论点没有支撑、某段话写得不够清楚。改完之后,文章质量明显提升。
LLM 也面临同样的问题。它每次生成输出,本质上是在「一口气」完成的,没有机会停下来检查。第一次输出常见的毛病有这几类:逻辑跳跃(推理步骤不完整,中间少了关键推断)、遗漏细节(任务里要求了某些点,但没有全部覆盖到)、事实错误(模型幻觉导致的错误信息)、表达含糊(意思到了但说得不清晰)。
这些问题,如果给 LLM 一个「回头检查」的机会,它自己是有能力发现并修正的。反思机制就是给它加上这个环节。
核心循环:生成 -> 评估 -> 改进
反思机制的核心思路来自 Self-Refine 论文,整个流程就是「生成 -> 评估 -> 改进」的循环。
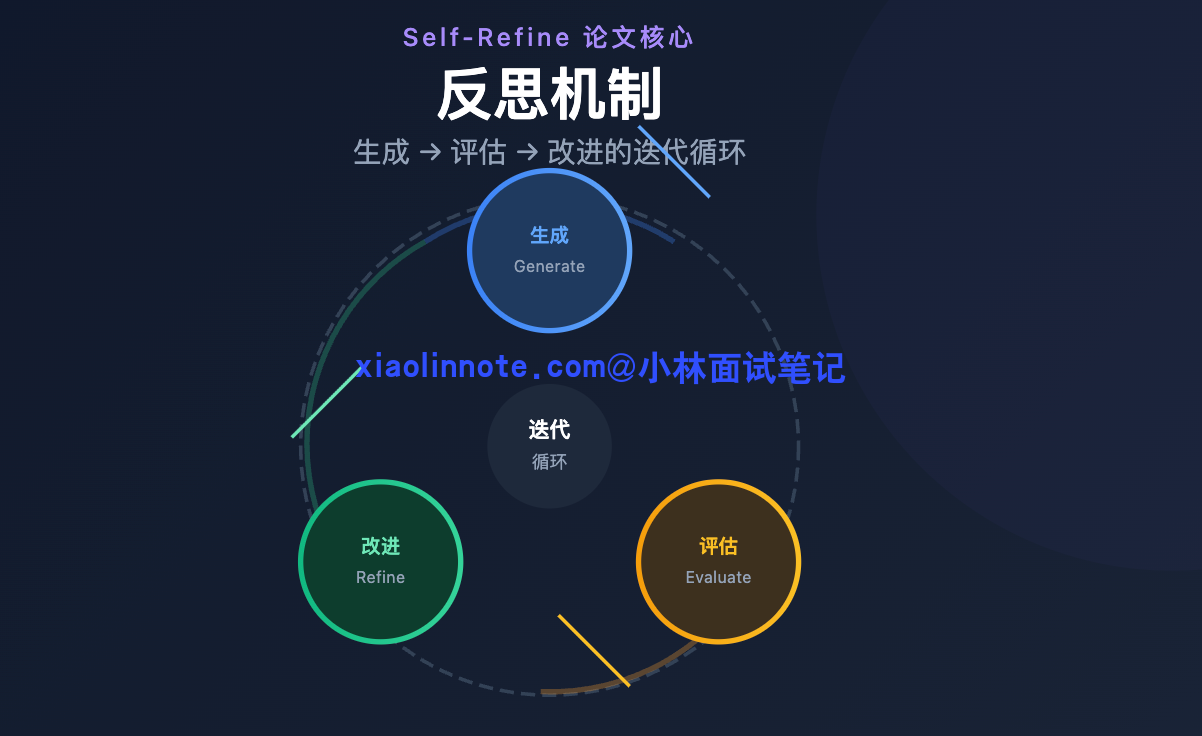
你可以用「草稿 -> 批阅 -> 修改」来类比:学生交出草稿(生成),老师批阅指出问题(评估),学生拿着批注修改(改进),改完的稿子再经过老师审阅,直到通过为止。

这个循环靠两个 prompt 来驱动。第一个负责评估,让 LLM 扮演「检查者」的角色,专门去找问题:
任务:{task}
当前输出:
{current_output}
请评估以上输出:
1. 有没有事实错误或逻辑问题?
2. 有没有遗漏重要内容?
3. 表达是否清晰准确?
如果输出已经足够好,回复「PASS」;
否则指出具体问题并给出改进建议。这个评估 prompt 的设计有几个值得注意的地方。首先,它给出了明确的检查维度(事实、逻辑、完整性、表达),而不是让 LLM 自由发挥。这很重要,没有方向的评估往往流于表面,LLM 可能只是说「输出看起来不错」,没有真正找到问题。给出具体维度,它才会有针对性地逐项审查。其次,「PASS」机制是必须有的,这是给 LLM 一个「足够好就停」的出口。如果没有这个机制,LLM 为了反思而反思,可能对一个已经很好的输出挑不必要的小毛病,反而把原本对的东西改错。
如果评估结果不是 PASS,就把评估意见喂进第二个改进 prompt:
原始任务:{task}
当前输出:{current_output}
评估意见:{reflection}
请根据评估意见改进输出:改进 prompt 有一个关键点:它同时传入了原始任务、原始输出、评估意见这三样东西,缺任何一个都会让改进变得盲目。只有任务没有原始输出,LLM 不知道在什么基础上改;只有原始输出没有评估意见,LLM 不知道改哪里;只有评估意见没有任务,LLM 可能改着改着偏离了原始目标。三者都在,它才能有针对性地修改,而不是把内容全部重写一遍。
两个 prompt 循环调用,直到 LLM 自己回复 PASS,或者超过最大轮次强制退出,整个外层逻辑不过是一个普通的 for 循环。
两个粒度:步骤级 vs 任务级
反思可以在两个粒度上触发,它们有不同的适用场景,代价也不一样,选哪种需要根据任务特点来判断。
步骤级反思是在每个工具调用或推理步骤完成后立即检查。它的好处是错误早发现早纠正,不会让一个小错误在后续步骤里层层放大。
想象一下 Agent 在做多步信息检索:第一步选了一个不精准的搜索关键词,后续所有步骤都在错误的信息上继续,到最后才发现,前面的工作全废了。
步骤级反思能在第一步就发现关键词的问题,马上纠正,后续步骤都建立在正确基础上。适合这种粒度的场景是步骤之间强依赖、前一步错了后面会全错的任务。代价是每一步都多一次 LLM 调用,整体延迟和 token 消耗会大幅增加,一个 10 步的任务可能实际要调用 20 次 LLM。
任务级反思是整个任务执行完之后做一次整体评估。好处是开销更小,整个任务只多一次 LLM 调用;而且从整体视角审视,能发现步骤级看不到的问题,各个步骤单独看都是对的,但整体结论前后矛盾,或者各部分之间衔接不自然,这种问题只有从整体视角才能看出来。

代价是如果任务中途某步出了大问题,到最后才发现,前面的执行都已经浪费了。适合步骤之间相对独立、最终输出的整体质量更重要的场景,比如生成一份报告。
多 Agent 互评:为什么「他人审视」比「自我检查」更好
除了单 Agent 的自我反思,还有一种效果通常更好的方式,多 Agent 互评:专门设置一个独立的 Critic Agent,让它来审查执行 Agent 的输出。
为什么独立的审查比自我反思效果更好?你可以类比代码 review 的场景:一个人写完代码自己检查,和让同事来 review,发现的问题质量往往不一样。自己写的东西自己看,容易「视觉疲劳」,会不自觉地补脑跳过问题,潜意识里倾向于认为自己的逻辑是正确的。

在 LLM 里同样如此:单 Agent 自我反思时,评估者和生成者是同一个模型,它在生成输出时形成的一套「内部逻辑」,做评估时也会沿用这套逻辑,对自己输出的错误不够敏感,容易陷入「自洽」。而独立的 Critic Agent 没有这种包袱,它的唯一职责就是「找问题」,视角更客观,更容易发现执行 Agent 自己看不出来的漏洞。
互评的具体流程是:执行 Agent 生成输出,Critic Agent 审查并给出具体批注,执行 Agent 根据批注修改,Critic Agent 再次确认。
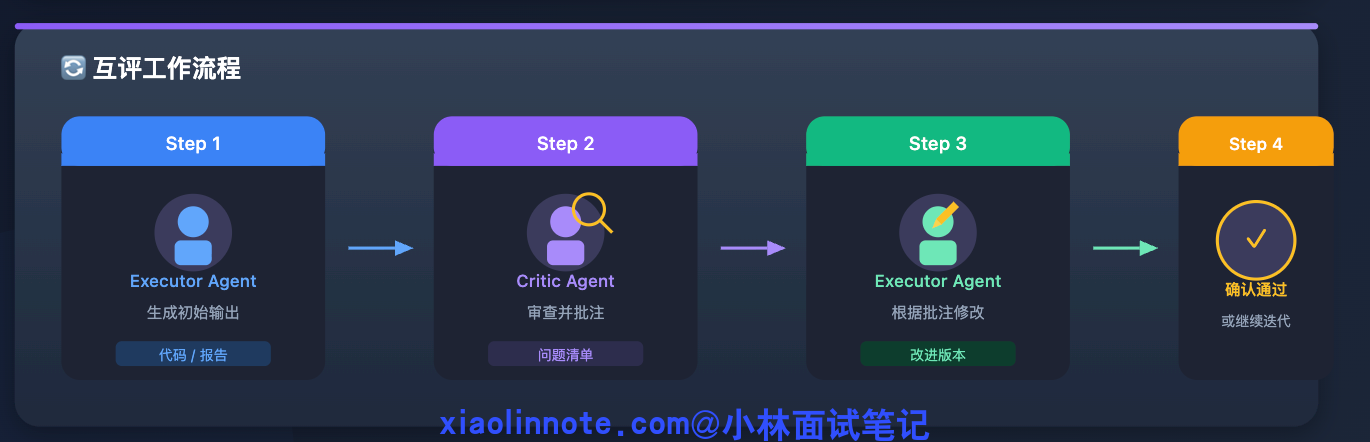
什么时候值得用这种方式?质量要求非常高的场景,比如生成代码后让独立的测试 Agent 来验证、生成分析报告后让事实核查 Agent 交叉验证。代价是又多一个 Agent 的调用成本,系统复杂度也更高,所以并不是所有场景都需要互评,普通场景用自我反思就够了。
工程权衡:怎么用才合理?
理解了反思机制的原理之后,还需要知道工程上怎么合理地用它,不然反而会让系统变慢、变贵、甚至陷入死循环。
什么场景值得开反思:输出质量要求高、错误代价大的关键节点,比如最终报告生成、重要决策的推理过程;以及任务比较复杂、LLM 容易遗漏细节的场景。
什么场景不值得开:简单直接的任务,比如格式转换、简单问答,加反思纯粹是浪费。实时性要求高的场景,一次反思至少多一次完整的 LLM 调用,延迟可能从 1 秒涨到 3 秒,有些应用场景根本接受不了。
最重要的是防死循环:必须设最大轮次,通常设 2-3 轮,绝对不能依赖 LLM 自己判断停止。原因是 LLM 有时会陷入「为了改而改」的循环,每次评估都觉得还有地方能优化,改完又有新的「问题」,每轮改动都很小但实质没有进步,系统就一直在转圈。硬性的轮次上限是唯一可靠的退出机制。
最后要对整体代价有清醒认知:3 轮反思 = 至少 3 倍的 LLM 调用,延迟和成本都线性增加,这是工程上做取舍的核心数字。反思是提升质量的有效手段,但不是免费的,用在刀刃上才有价值,不是每步都做。
15. 如何设计多 Agent 的协作与动态切换机制?
💡 简要回答
协作靠两件事:消息传递和共享状态。消息传递是 Agent 完成自己的工作后把结果发出去,下一个 Agent 取用;共享状态是所有 Agent 共同读写一个状态对象,记录任务进展和中间结果。动态切换靠 Orchestrator 来做,有两种方式:一种是静态路由,提前写好规则「任务类型 A 就找 Agent X」;另一种是让 LLM 动态决策,根据当前情况实时判断该把任务交给谁。我的实践是两种混用,主流程用静态路由保证稳定,边缘情况才交给 LLM 动态判断。
📝 详细解析
多 Agent 系统里,分工解决了「谁来做什么」的问题,但还有另一个问题没解决:各个 Agent 做完自己的事之后,怎么把结果传给下一个 Agent?下一步该叫哪个 Agent 来接棒?这就是协作机制和切换机制要解决的事。
先说协作:Agent 之间怎么传递信息
你可以把多 Agent 系统想象成一个公司里的多个部门:研究部、开发部、测试部各司其职。部门之间传递信息,有两种方式。
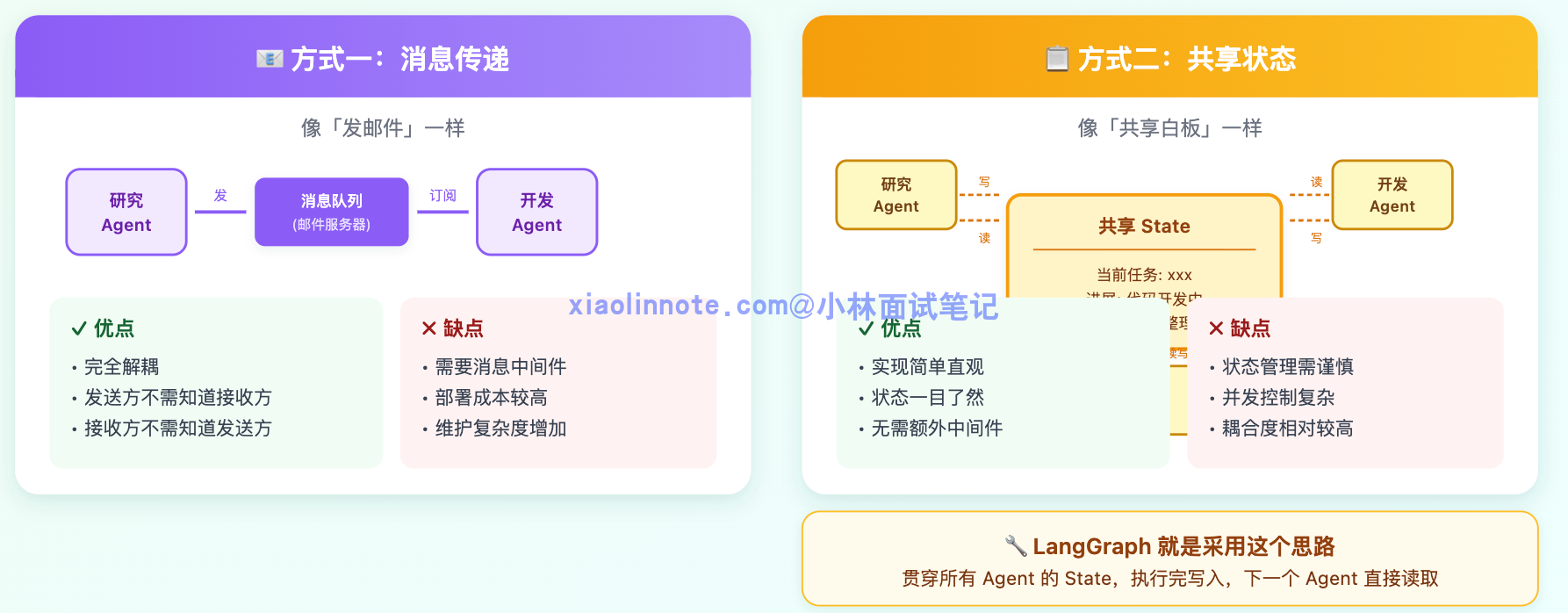
第一种方式,像发邮件:研究部完成了资料整理,就把报告「发」出去,开发部收到邮件后再开始工作。这就是「消息传递」的思路,Agent 完成自己的工作后把结果发送到一个消息队列,下游的 Agent 订阅自己感兴趣的消息,取到了再开始处理。这种方式最大的优点是解耦,研究 Agent 不需要知道谁在等它的结果,只管发;接收方也不需要知道消息是谁发的,只管处理。缺点是需要一个「邮件服务器」,也就是消息中间件来维护这套机制,部署成本稍高一些。
第二种方式,像共享白板:公司里所有部门都盯着同一块白板,上面写着「当前任务是什么、进展到哪一步了、各部门完成了什么」。研究部写上「资料整理完成」,开发部一看,知道可以开始了,于是接手并写上「代码开发中」。这就是「共享状态」的思路,所有 Agent 都读写同一个状态对象。LangGraph 就是用这个思路来设计的,它有一个贯穿所有 Agent 的 State,每个 Agent 执行完就往 State 里写入自己的结果,下一个 Agent 直接从 State 里读取前面的产出。
这两种方式怎么选?如果各 Agent 之间的依赖关系比较强,前一步的结果要直接传给后一步,用共享状态更直接。如果你希望 Agent 之间尽量解耦,互相不知道对方的存在,用消息传递更合适。
再说切换:Orchestrator 怎么决定叫谁
「切换」就是决定下一步把任务交给哪个 Agent,这个决策动作在系统里叫做「路由」。Orchestrator 就是那个负责做路由决策的角色。
路由有两种策略。
静态路由,就是提前把规则写死。比如任务描述里包含「搜索」就找 Researcher Agent,当前步骤已经是「代码写完了」就找 Reviewer Agent,找不到匹配规则就回到 Orchestrator 兜底。这就像工厂流水线,每道工序完成后,下一步去哪个工位是固定的,效率高、可预测、好调试。但它覆盖不了你没预料到的情况,如果任务走了一条你没定义规则的路径,系统就不知道该怎么办了。
动态路由,则是把「下一步找谁」的决策权交给 LLM 来做。Orchestrator 把当前任务描述、已经完成了什么、还有哪些 Agent 可以调用,全部告诉 LLM,让它判断「现在应该叫哪个 Agent 来做下一步」。这种方式的优点是灵活,能处理任何你没预先设计的路径,任务走到一个边缘情况时,LLM 也能做出合理判断。缺点是每次路由都要多一次 LLM 调用,增加了延迟和成本,而且 LLM 偶尔也会路由错,系统行为的可预测性就降低了。
两种路由策略的对比可以用一张图来理解:
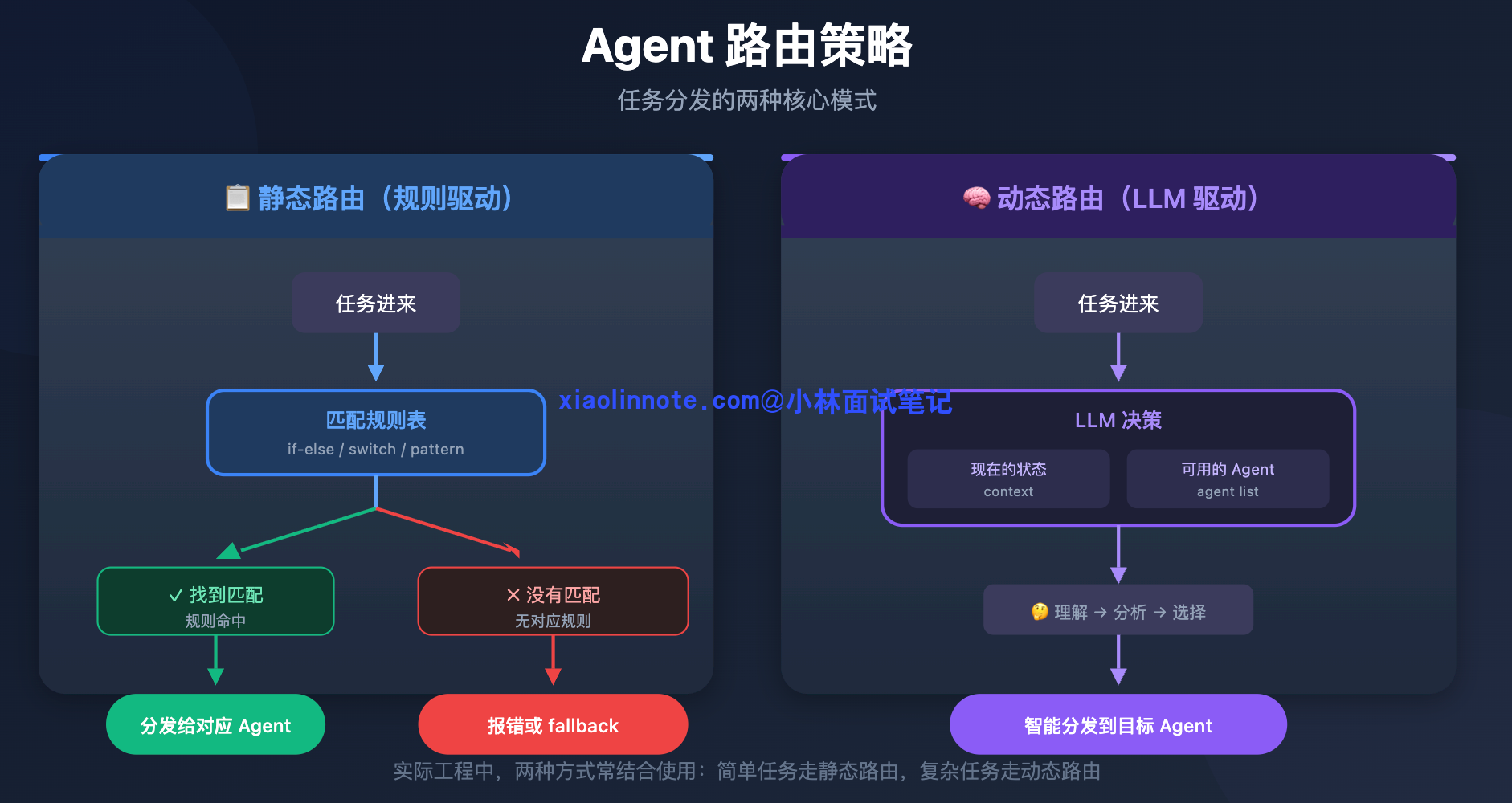
工程上怎么用
实践中最稳健的做法是两种路由组合用:主流程用静态路由,把确定性的节点切换都写成规则,保证绝大多数情况下系统行为稳定可预测;只在遇到没有匹配规则的边缘情况时,才交给 LLM 动态决策。这样静态路由负责「保底」,动态路由负责「兜住异常」,两者互补。
通信方式的选择同理:如果你的多 Agent 流程是一条相对清晰的流水线,各步骤之间有明确的前后依赖,就用共享状态,简单直接;如果你的系统需要让多个 Agent 独立并行、互相不感知对方的存在,就用消息传递,解耦清晰。